引言
无论AI技术如何变迁,其拉动他的算法、算力和数据的三驾马车并未变过。其中,最不起眼的莫过于数据,如若不是scaling law被事实证明,可能大多数人对于数据和AI效果的关系约莫只停留于那一句梗:
有多少人工,就有多少智能。
这一句双关的玩笑,既取笑了曾经的AI智能能力的边界(不过如此,不达到预期),也取笑了智能的背后其实是靠人工的堆叠,无论是堆在标注,还是堆在那些“躲在机器人里面的全球化客服人员” 。
只是这句玩笑,对于我们这些AI从业者来说确实残酷是透着苦味的,就我们的创始团队成员来说,在开始「JoinAI 卓印智能」的旅程之前,亲身经历了各种各样的,因为无法获得合适的/足够的训练数据让AI效果停滞不前、流产、够不到那本来触手可及的舞台的事,遍布自然语言和计算机视觉的疆域。
近年来,为什么会有AI霸权的说法出现,为什么真正好用的AI总是出现在大公司,一个不可忽视的因素是,对初创公司来说,高昂的训练数据费用很可能就是他们翻不过身的大山,而没有高质量的训练数据,AI的智能无从谈起。
算法工程师们为了在微弱的预算下拿到最好的效果,可以说是使劲儿浑身解数,诸如「小样本学习」类的「低数据、低算力」的模型的各项研究和其惨淡的工程应用效果,都不无诉说着算法工程师们被迫:屎上雕花的无奈。
在这一点上,感谢OpenAI的坚持,通过无懈可击的事实,为我们这些AI从业者证明了scaling law切实可行,也证明了最朴实而简单的路线可能反而才是捷径👇。
- 大力出奇迹,最就是短的路径。
- 为你的AI收集尽可能够的数据,在符合你训练目标的基础上,the more the better。
现有数据可以实现AGI吗?
假设你希望你的AI达到的自己的完美效果是个圆,你就需要那么多、且覆盖面极广内容足够丰富的数据来支撑这个圆满,就像这样👇:

要达到当前AI的完美效果所需要的总训练数据
那么这个圆必须由这些类型的数据构成:
- 一部分:可见,可得,但不可用,
- 一部分:可遇不可求
- 一部分:可见,可得,但是不免费
- 一部分:可见、可得、免费但是数量少的可怜
可见,可得,但不可用的数据
这种数据就像是你邻居家里的贵重藏品,你可以看见,物理意义上你也可以得到,但是若你这么做了,其结果可能是:你被你的邻居一枪崩死,或者支付高昂的罚款,或者去局子里过段难忘的人生回忆。
这样的数据非常常见,圈层从最基础的互联网上随手可得的没有明确表明版权但实际上可以追述版权所属的数据,到使用起来会违反数据安全法规的数据,甚至属于他人的私域数据。它们都具有极度珍贵的价值,对你的AI非常有益处,可后两者,你无能为力,你所能做的,也只有在前者里打一下擦边球,但是很可能,你所从事的AI项目并不那么幸运,几乎不存在前者,譬如,如果你做的是自动驾驶的话,前者,基本就微乎其微。
所以,很遗憾,因为你没有办法得到这部分,你的数据构成不了一个圆,无法圆满,他们得剪去一些部分,如此,你还剩下一个,譬如一个矩形。
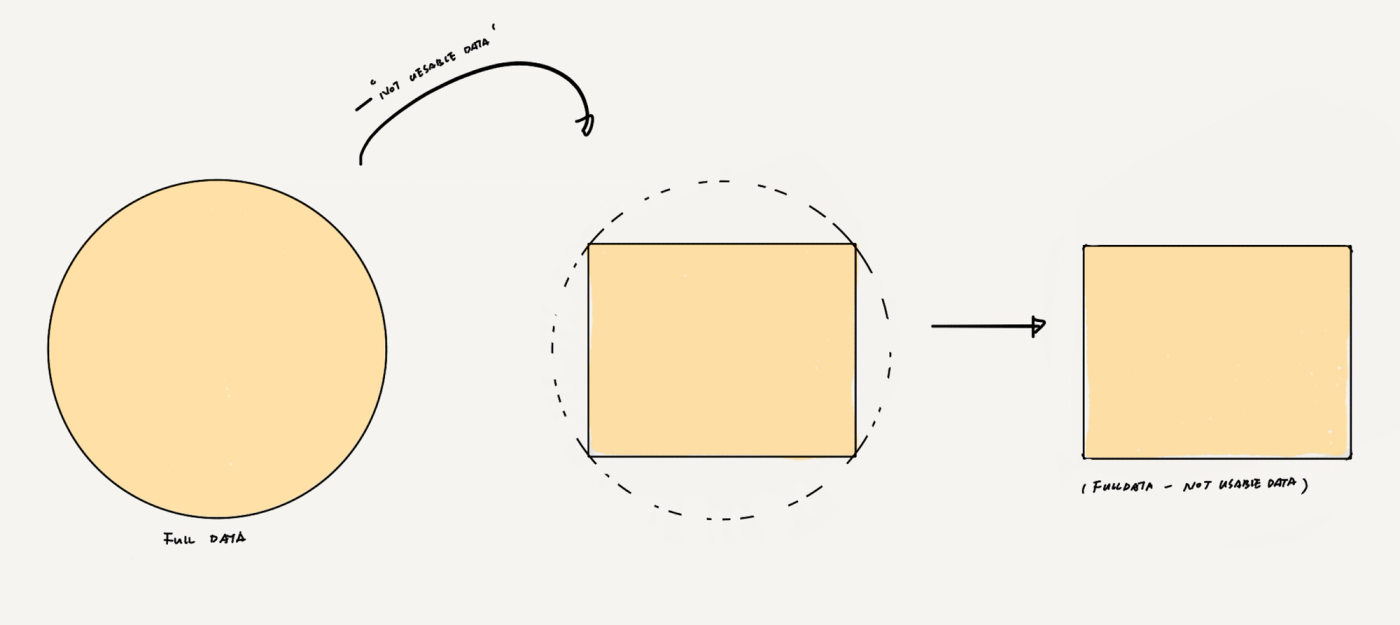
当前AI的完美效果所需要的数据-隐私数据
当然,不同细分行业里情况不尽相同,每个矩形,边长大小不同,但总归是,最大也只能得到一个正切矩形。(如上图)
可遇不可求的数据
这类数据就像我们希望遇到的Mr/Miss Right,是最适合的,也是最想要的,但极其难获得,它们有一个更为人熟知的名字,叫做corner case。在很多不得不追求AI效果无限接近100%的场景里,corner case比Mr/miss right还必须,但稀缺。
还是以刚才提到过的自动驾驶举例,假设你每天开车上下班,你要连续开多久,才能遇到一个不要命的行人,突然横在你的车子前面,或者冲着你的车子跑来?最好是不要遇到对吧,但是对于一个自动驾驶系统来说,它必须要对这种情况做好充足的准备。可这样难以「遇见」的数据又何止一个“不要命的行人”。
所以,corner case也很少,你的矩形还是要被剪去一些部分,现在你只剩下一个三角形了
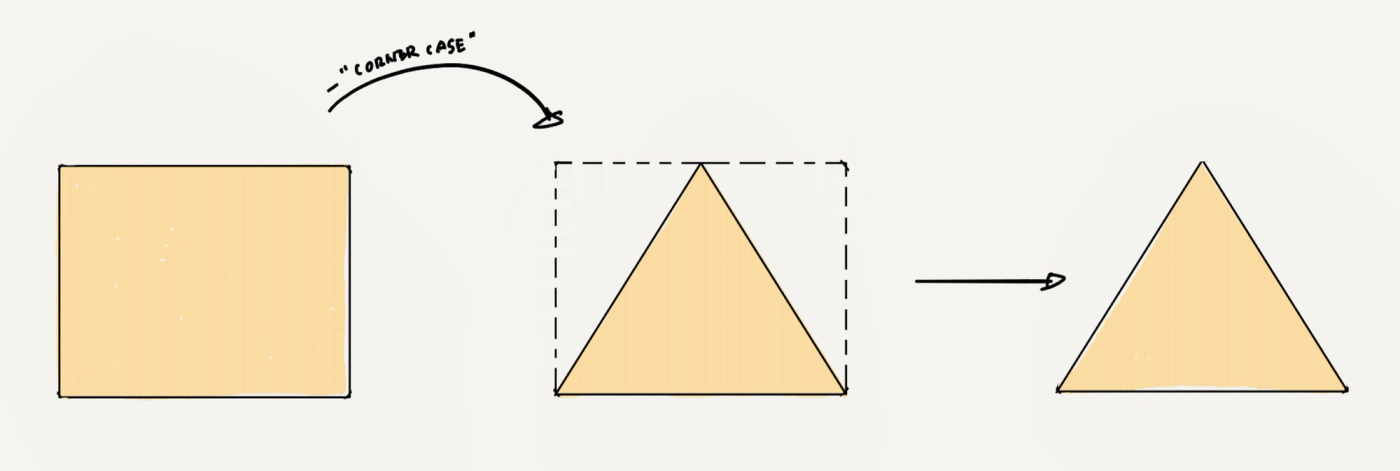
当前AI的完美效果所需要的数据-隐私数据-CornerCase
矩形里的最大三角形形态会有不同,正如每个细分行业里、不同公司的AI所遇到的corner case的问题也是不同的,但是根据我们在数据课上学到的基础,在矩形里的最大三角形,就是这样的直角三角形。(如上图)
可见,可得,但是不免费
现在,你只剩下一个三角形的数据了,这部分也就是可以用钱买到的我们最熟悉的采标数据,虽然只有一个三角形了,但是起码它是有稳定性:稳定地用钱购买
然后这是它现在的一个基础获取流程:
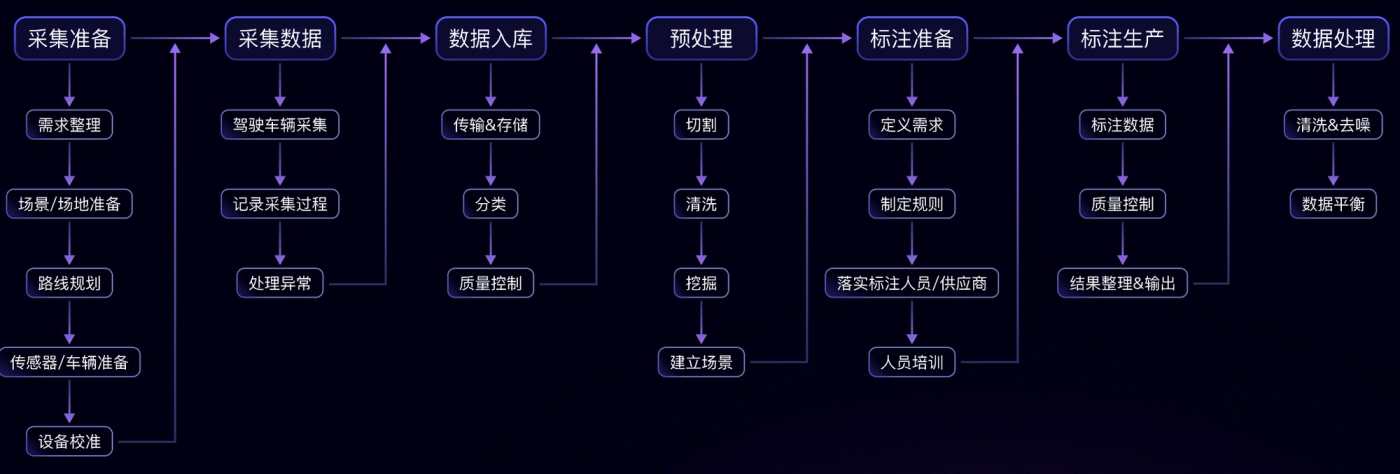
标准的采标数据获取流程
一个复杂的,冗长的,标准瀑布式流程,从流程结构上就可看出,即便是不考虑每一个step上参与的人引起的人月神话,光是任何一个环节出现问题,都是瀑布流式的返工和浪费。这种制造流程,更不用说,即便是在big company内部,这样的训练数据准备流程连工业2.0的水平都没达到,也就是说,为了这份稳定可购买,需要支付高昂的成本,对于绝大多数AI项目方来说其资金储备+造血能力绝对不足以支撑这个三角扩张到scaling law的边界。
更何况,在这个稳定三角形里,你需要面对的问题也不见得只剩下钱。譬如,为了节省成本,你不得不对一部分流程进行外包,为了得到更好的质量,确保供应商的服务不会因为独家而下降,你通常需要同时拥有多家供应商,如此,你还需要进行额外的供应链管理,但即便如此,你也无法从根本意义上保证多家供应商能够提供如出一辙的质量保证。如果你是项目的负责人,你最不愿意看到的可能是看到你高薪聘请的算法研发人员,花了它们80%的时间在数据处理和准备上,虽然,你必须得承认这可能真的是事实。
所以你的三角形还要打折扣,大概率没办法是最大面积下的直角三角形,比如👇:
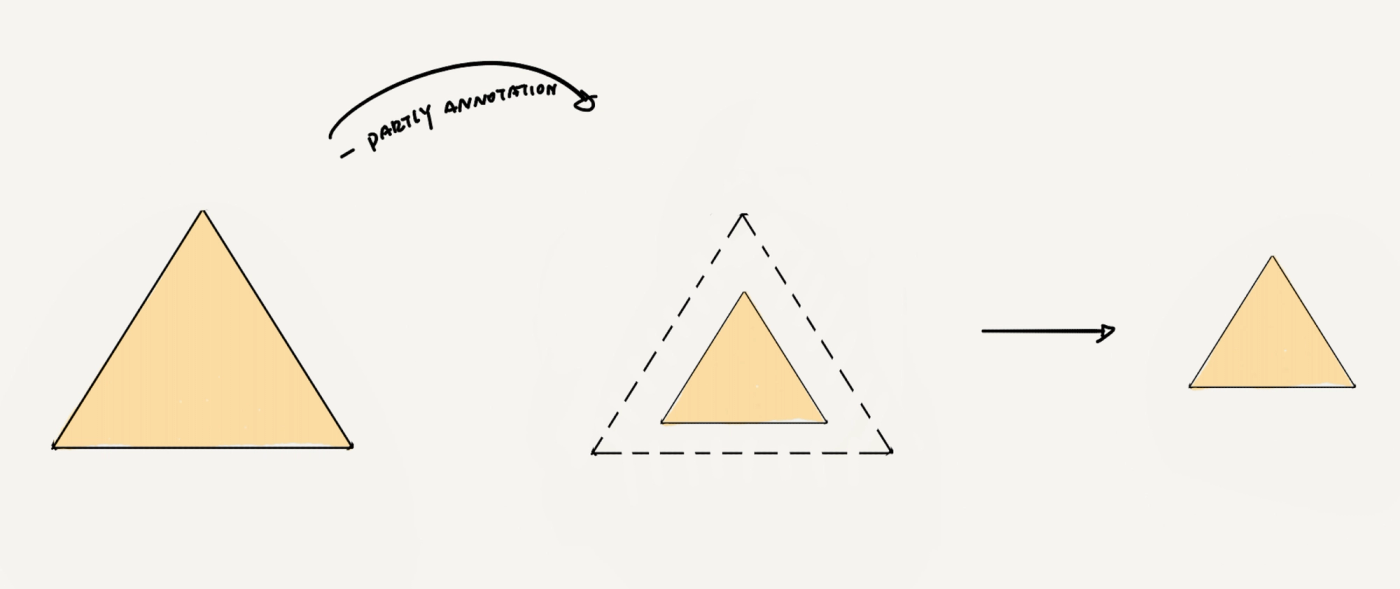
当前AI的完美效果所需要的数据-隐私数据-CornerCase-部分采标数据
可见、可得、免费但是数量少的可怜的数据
剩下的部分,你会自然的想到还有开源数据集,当然,它可以作为补充。
无比感恩开源社区,他们总是能贡献出一些免费可用的好东西的,只不过,有且只有那么多,且,对所有人都一样,你知道总是很难指望你可以通过它们得到惊艳的预期效果,他们通常都是更多的用来在前期lab阶段的尝试性验证或者增加测试集的丰富程度。
我必须要指出上述的阐述存在一定的极致纯净的成分,现实的情况下,支撑各家的AI效果的数据图形形态,大约既不是矩形也不是三角,是混合体或者一些边缘没有那么清晰的图形
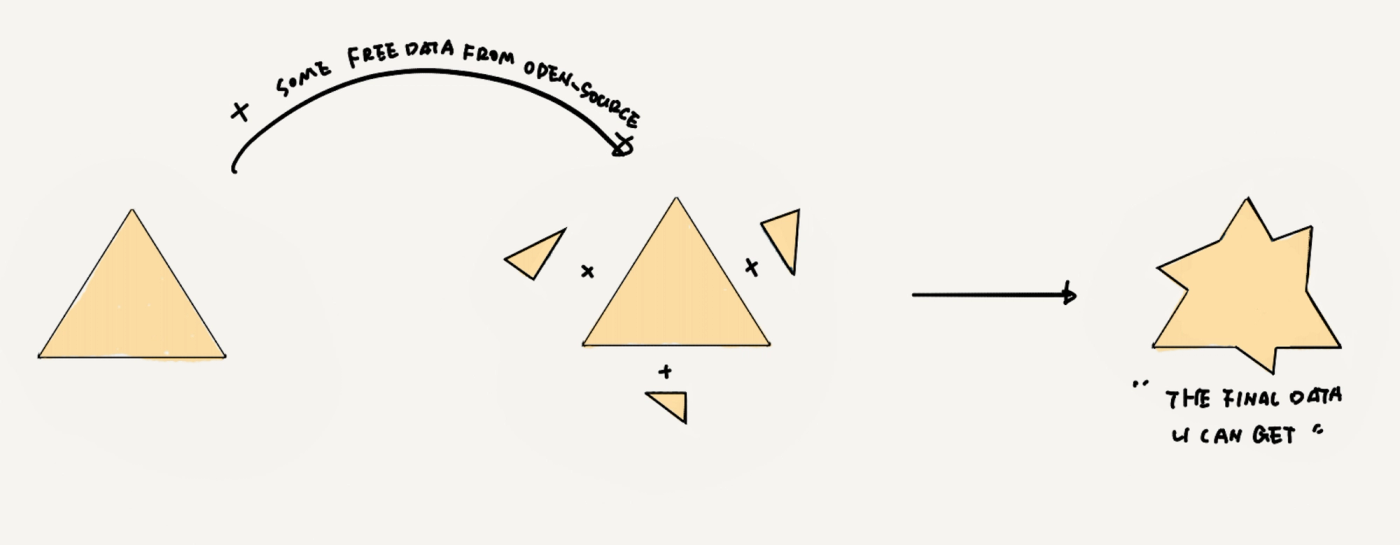
当前AI的完美效果所需要的数据-隐私数据-CornerCase-部分采标数据+一些开源数据
值得一提的是,还必须指出一点,不同行业形态下的AI,的corner case和采标数据占比是完全不同的,譬如很多工业场景下,甚至可能是这样的,而且,可能你找不到任何真正可用的开源数据集。
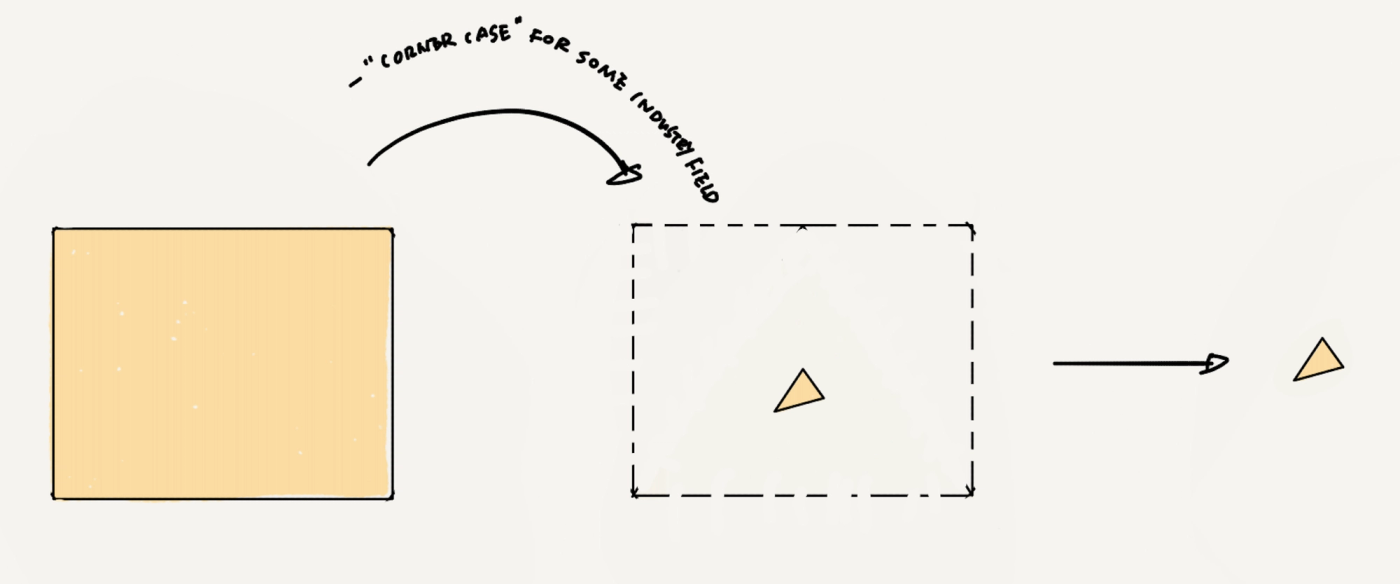
一些工业场景下的可获取数据(工业场景下几乎全是“corner case”)
只是无论如何,没有任何一个AI项目可以获得一个正圆的完美数据。即便是OPENAI,至多也就是最接近正圆的那个。自然,如果我们只能持续通过现有方式获得数据,恐怕会连自己AI的能力边界都无法触及(那个正圆)更不要说是AGI所需要的了。
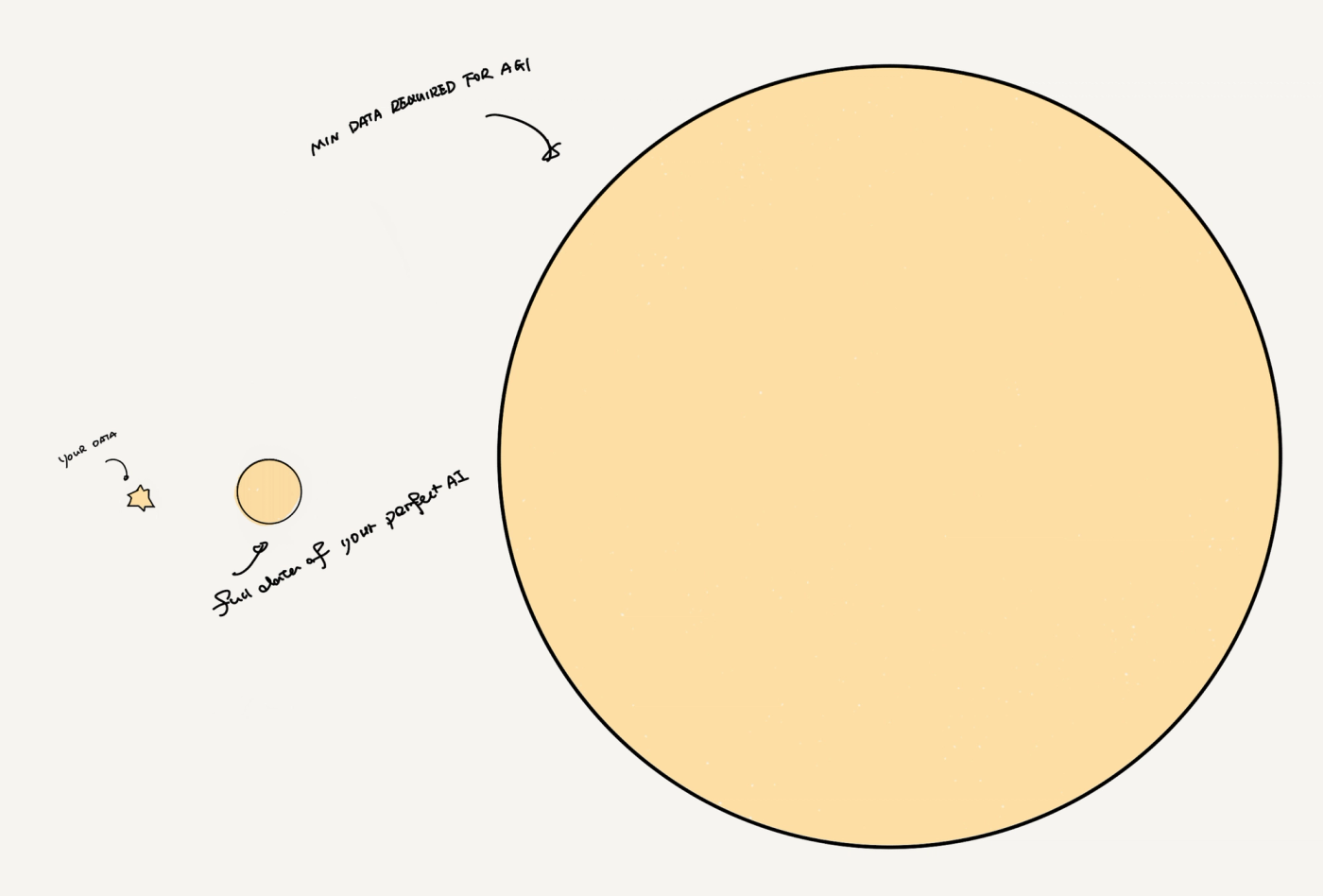
你能得到的数据 vs 当前AI的完美效果所需要的数据 vs AGI至少需要的数据
除非,我们可以通过一种方法,它可以用极低的成本,创造大量的数据,这个数据可以实现随心所欲的corner case,可以具备隐私的边界,又可以越过隐私的私欲的门槛。
这样理想主义的梦幻方式真的有吗?
其实是有的,尤其是在生成式AI和世界模型已然开始崛起的今天,合成数据已逐渐在AI训练中扮演一个日益重要的角色,成为真正解放AI生产力的最优解,开启AGI奇迹大门的梦幻密钥。在JoinAI努力构筑的未来中,训练数据对于AI就会像我们人类现在用电一样,即时取用、便宜实惠且没有焦虑。
虽然这样听起来有点扯淡,甚至不乏有人在听到用「合成数据」来训练时候认为存在悖论,但无论是在学术界还是商用领域,通过「合成数据」扩充训练数据集,提高训练效果却并非是新鲜概念,更不是大模型时代下才缔造的新鲜产物。
合成数据技术早已日趋成熟
在计算机视觉领域,合成数据的概念最早可以追溯到初期实验阶段,当时研究者开始使用基本的图形引擎生成图像以测试算法性能,而后在GAN(生成对抗网络)和VAE(变分自编码器)技术的逐渐成熟后,合成数据开始不断被正式用来创建数据集参与模型训练,在2014年,在硅谷就已经出现通过「合成数据」对企业提供服务的公司,在今年,Datagan更是斩获了Scale Venture Partners 投资的5000万美元B轮投资。
现今在图像-合成数据领域,其底层主要有以下三种主流技术路线:
- 以传统计算机视觉算法为首的传统数据增强技术(譬如前文提到的GAN)、
- 仿真技术或者是引入了nerf技术的新一代仿真技术
- 以端到端模型为核心的生成式AI。
以GAN为首的图像技术在许多任务上表现的很好,尤其是在单目标的生成上,谷歌早就证明了即便是以GAN来制作训练数据集也可以在测试集上达到sota的效果。
仿真技术原本的主要应用并不在训练数据获取上,尤其是譬如在自动驾驶里,仿真系统被普遍用来进行模拟测试。但如果一个用来测试的系统里提取的数据能够同时用于辅助训练,听起来的确是具有其独特的吸引力和优越性,可事实并非如此简单。当研究人们使用了譬如当时认为最具有物理逼真度的GTA的游戏数据来代替仿真数据(因为GTA的逼真性高于当下的仿真系统)进行训练测试的时候却发现特征无法收敛,推理出这种方式下产生的数据和真实数据之间存在次元壁。这一问题在生成式AI技术出现后有了新的研究方向,一方面,以Nerf技术加持仿真系统,可以降低次元壁的影响,但其问题在于,这种模型的训练依然受限于真实采集的数据,无法达到无中生有,其次,仿真模拟产生的数据的次元壁虽然有所降低但依然无法破除。
另一方面,GEN AI的应用催生了以端到端模型为核心的生成式AI技术为核心的「合成数据」技术,使用这种技术生成的数据在广泛性、逼真度、可控性和拓展性上均都有显著优势,最重要的是不存在数据次元壁。
更何况事实胜于雄辩,我们也在实践中,在商业落地的过程中以实际数据在甲方的验证中得到了正向反馈,譬如我们在自己的官方网站homepage中第6屏呈现的数据,就是获得了甲方同意展示的真实数据。
争议 or 挑战?
当然,我们并不认为这种技术是完美无缺的,无论是GENAI还是世界模型,从技术角度来说我们都只认为它是一个开始,存在争议和有待提高之处自然有很多。
譬如有人认为合成数据根本上与传统数据不同,因为它是通过模型生成的,缺乏直接的人类元素。这样表明合成数据可能会错过在人类生成的数据中自然出现的微妙之处。然而,我们认为从事实来说,由于生成数据本身与生俱来的随机性,能够很好的cover这一问题,从某种意义上来说,完全的随机甚至能囊括人类有迹可循的规律性。
也有人虽然赞赏「合成数据」在改善数据质量以提升模型性能方面的实用性,但对合成数据是否能够扩展模型的知识范畴超出模型本身可以推断的范围表示担心,这种担心我们认为和另一种担心是有具有相关性的。
这种担心是关于一种错误使用合成数据可能回导致的一个重大风险:可能创建一个回音室,其中AI系统循环地在由类似系统生成的输出上训练,可能导致创新停滞,也就是说:在以前的AI系统的输出上训练AI模型可能会导致一个反馈循环,限制了新模型超越旧模型能力的潜力。或者我们换一个词,这种情况下可能会出现模型自噬,但我们认为不需要过度担心,产生模型自噬的核心并非在合成数据本身,而更多在于应用方法上,关于这部分分享,我们推荐阅读我们的另一篇文章:《合成数据会导致模型自噬吗?》
对任何争议,我们都乐见其成。
有争议意味着被真实的投入使用,同时也意味着问题将会无所遁形。JoinAI在合成数据上的道路才刚刚开始,为了实现我们的梦想,这条路我们会坚定不移的走下去,正因为如此,我们欢迎任何争议的产生,JoinAI的每一个人都将会对争议保持最open和乐观的态度,对于秉承着最朴素的技术信仰的我们来说,困难总是没有解决方案多的。
结语
每当人们说起「AI的智慧离不开训练数据」,无论以何种形式去表达,都不改变这是一个听起来很难让人兴奋、完全不性感的、令人无奈的事实。比起这种朴实无华的真理,我们难免总是更喜欢以小搏大、四两拨千斤的故事,就譬如哪怕是那个曾经红极一时的小样本学习(通过少量训练数据也可以得到很好的AI效果的设想)。
从人性角度来说,我们很难去克制自己不去寻找捷径,更何况以科学辩证的角度来看,即便ChatGPT证明了scaling law这种蠢办法才是捷径,也不等于「智能涌现的道路就只有scaling law这一条」。
只是,无论scaling law是不是AI唯一的出路,只要人类不停下对AI/AGI的探索,就仍然必须要面对「现实世界已有的存量数据」无法满足训练的基础条件的事实,而「合成数据」及其相关技术路径的探索,已是人类的梦幻捷径。
在JoinAI的数据方法论里,有一条核心原则公式:
更好的数据=(更好的数据AI匹配度 x 更好的获取数据的方法 x 更好的选择数据方法) /更好的管理数据的方法。
而唯有最好的的合成技术,才有能够同时让()三项因子达到完美的最大值潜力。而这也是JoinAI|卓印智能一直在努力的事。
用更好的数据,为每一个人带来更好的AI,直到永远。





