模型自噬研究
模型自噬的概念取自「细胞自噬」[1]特指这一代模型在仅通过完全使用用上一代模型生成的合成数据训练,这一代模型的性能会因为自我消化而下降。
我们在研究模型自噬的过程中,发现了很多论文都有相关的研究,这里我们简单介绍三篇论文的工作。
在《Self-Consuming Generative Models Go MAD》[2]论文中,讨论了合成数据可能出现的自噬(自我消耗)现象。
论文中,提出了三种自噬循环:
- 完全合成循环:每一代模型仅使用从上一代模型合成的数据进行训练。
- 合成增强循环:每一代模型使用来自前一代模型的合成数据和固定的真实训练数据集的组合进行训练。
- 新鲜数据循环:每一代模型使用来自前一代模型的合成数据和每一代的新真实数据的组合进行训练。
论文作者发现,如果没有足够的真实新鲜数据,未来的生成模型注定会患上模型自噬障碍,即它们的质量(精确度)或多样性(召回率)将逐渐降低,并且生成的会被放大。
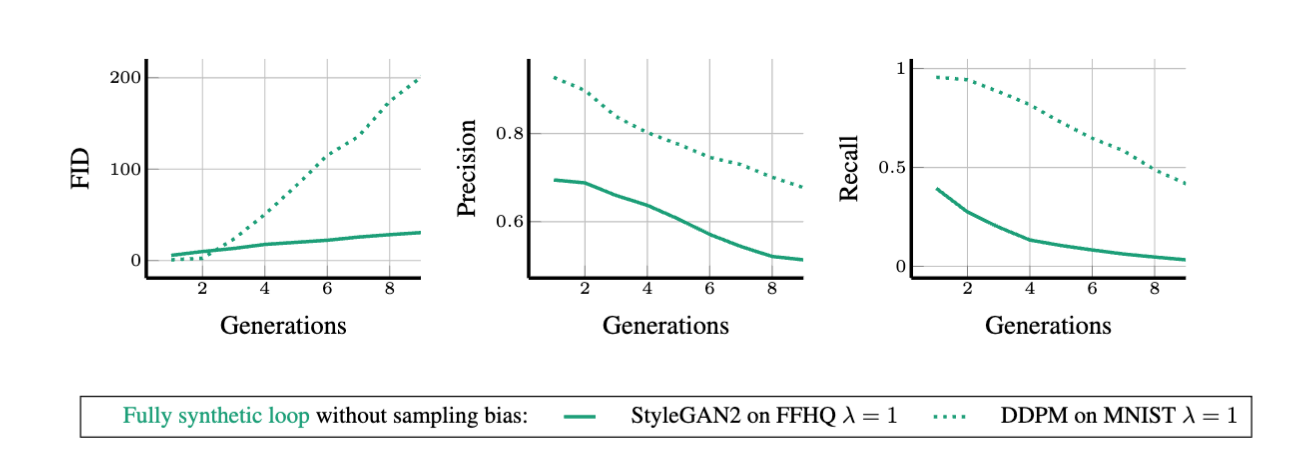
论文三个数据循环的效果
图1
上图1是论文上的图,表述完全合成循环中专门针对合成数据训练生成模型而没有采样偏差,会降低合成数据的质量和多样性,
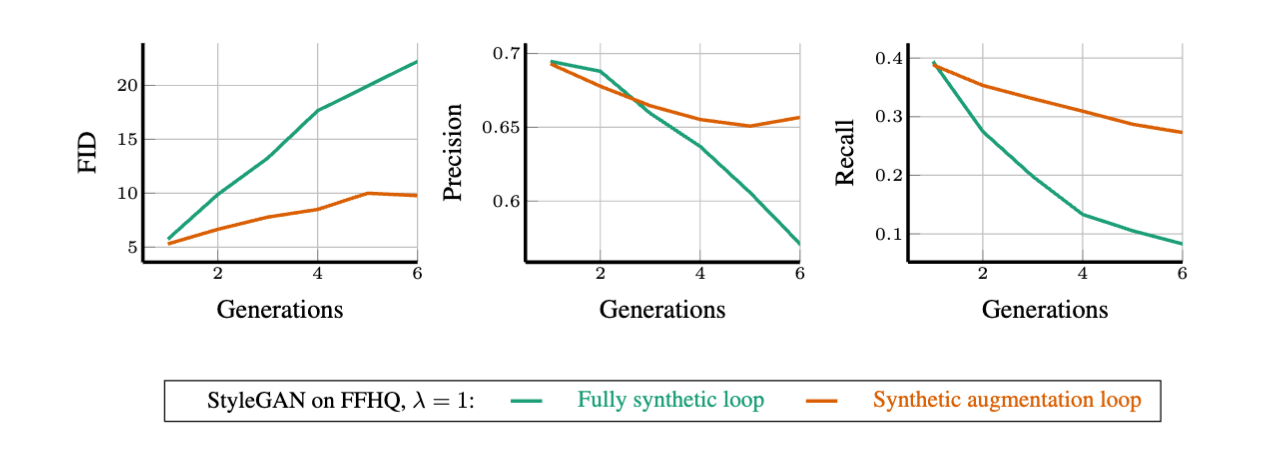
合成增强循环效果
图2
图2为论文上的图,表述合成增强循环,固定的真实训练数据可能会延迟但不能阻止模型自噬。
这篇论文也提出了解决办法,那就是新鲜数据循环,实验得到有限数量的合成数据可以改善新数据循环中的分布估计,因为合成数据有效地将以前使用的真实数据转移到后代并增加了有效数据集大小。
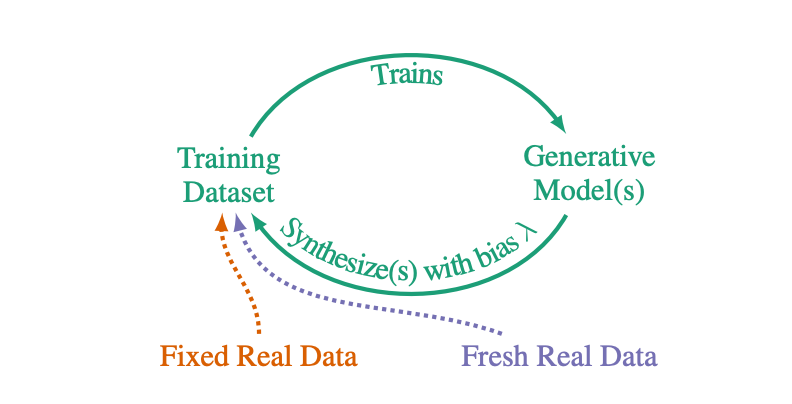
数据循环图
而且,这篇论文的作者发现,在新数据循环中,采样偏差会减少可接受的合成样本大小。说明,我们需要了解多少稀缺真实数据才能避免陷入模型自噬。
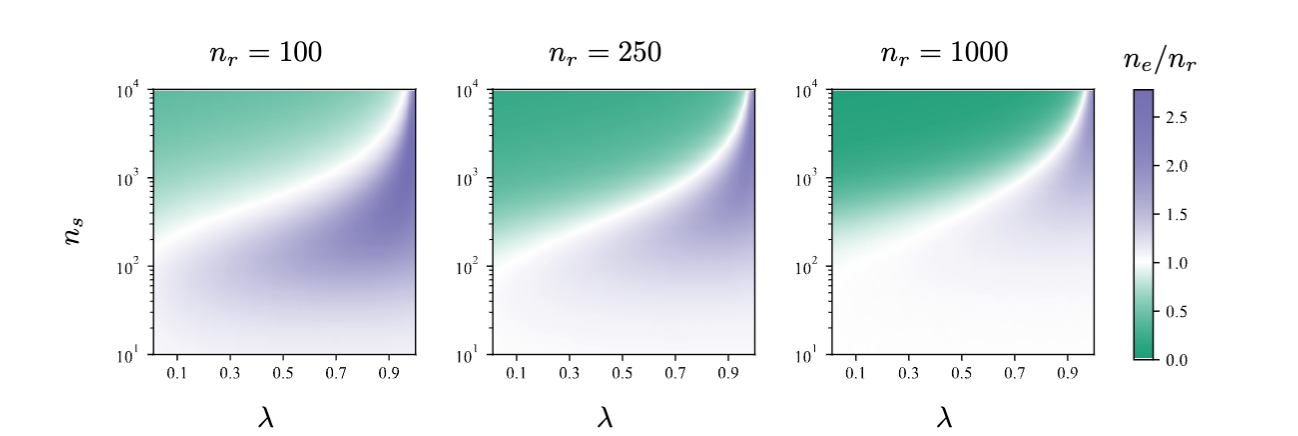
生成数据加入多少比例的效果图
在另外一篇论文《Beyond Model Collapse: Scaling Up with Synthesized Data Requires Reinforcement》[3]中,论文作者们发现在大模型微调中,使用合成数据,如果不使用强化学习,会陷入模型崩溃。
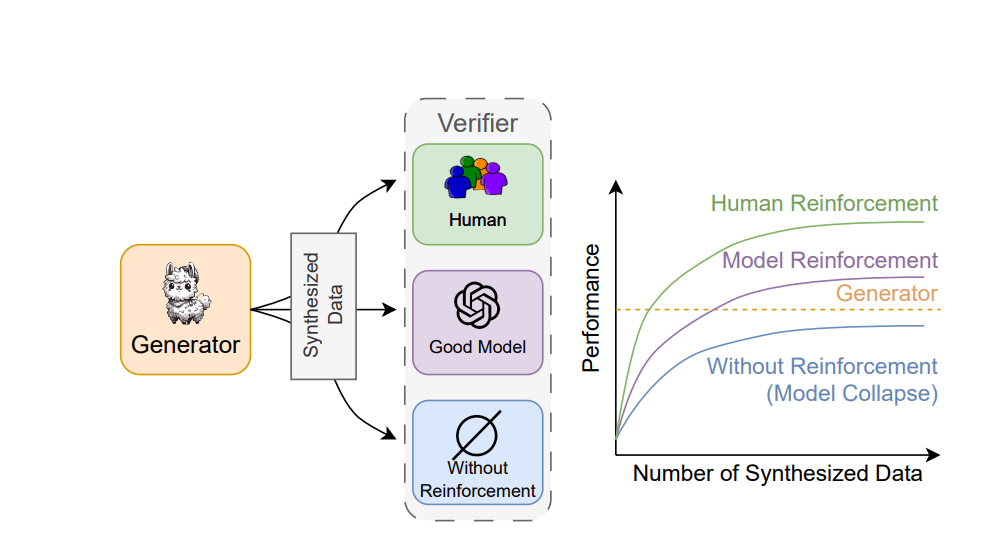
论文合成数据与有无强化学习的效果总结图
作者发现在微调的大模型如果只使用合成数据,会导致模型性能下降,如果增加一个选择器(强化学习),则不会导致性能下降。
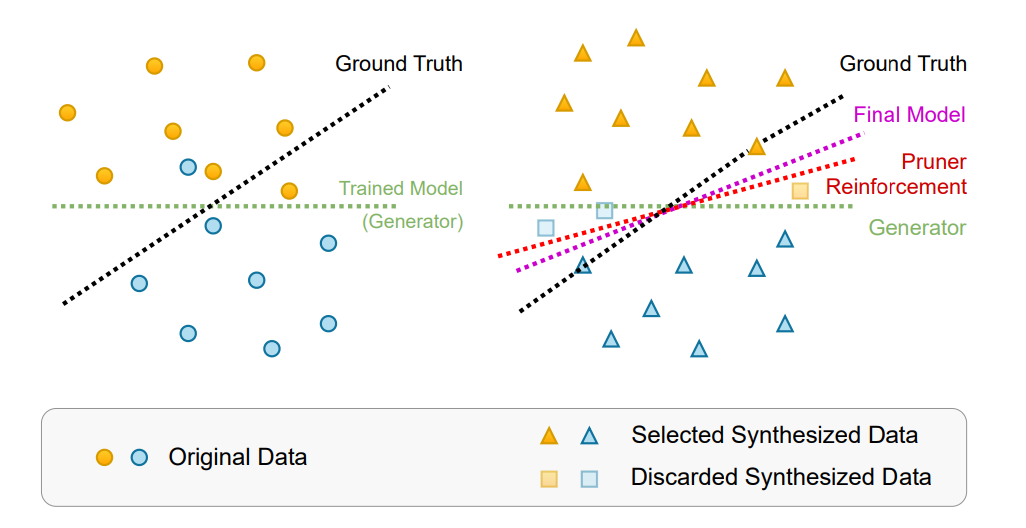
原始数据与被选择过的合成数据对比图
在另外一篇论文《Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing》[4]中,研究者们还提出了一种针对LLM的大规模对齐数据的自合成方法,而且效果达到了SOTA。
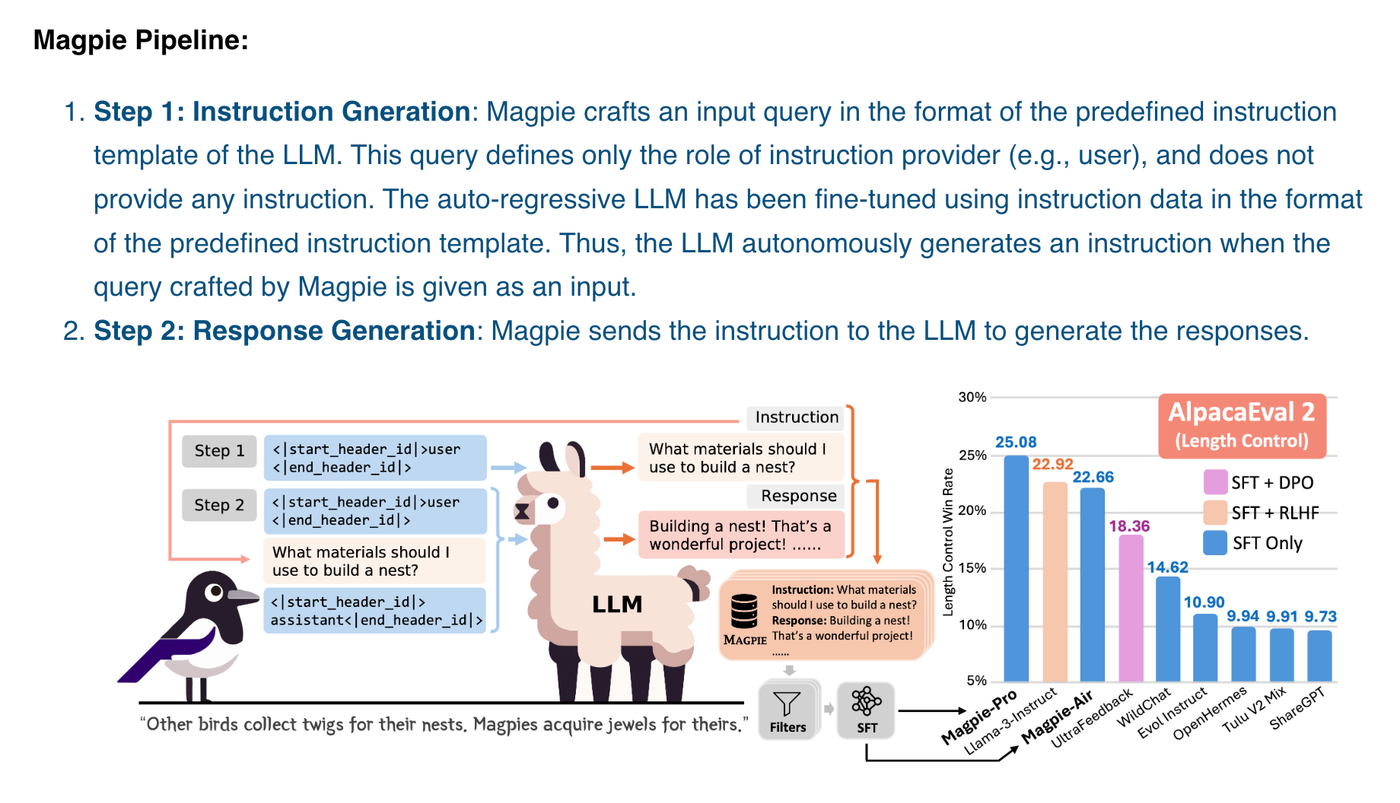
合成数据SFT步骤
综合上面介绍的三篇论文可以得出结论: 在使用合成数据训练模型的过程中,保持训练数据的多样性并筛选过滤,就不会有自噬等隐忧出现。
JoinAI 在合成数据上的工作
第一步:利用合成数据增强数据多样性,提高模型准确性。
在很多AI应用场景中,获取大规模高质量的真实标注数据非常困难和昂贵,尤其是对于一些长尾、极端、异常情况。合成数据可以通过模型生成等技术生成这些样本,,弥补真实数据的不足。 通过增加训练数据的多样性,可以让模型学习到更全面的特征模式,提高其泛化能力,从而在实际应用中取得更高的准确率。合成数据在这一阶段主要是作为真实数据的补充。
JoinAI 开发了simulaix,一个自研的基于AIGC的,AI训练数据生成引擎。我们通过生成大量多样化的数据集,包括那些在现实世界中难以捕捉的长尾场景,大幅降低了数据采集和标注的成本(降低到现有的1/10甚至更低)。
据Plug and Play预测,到2030年,全球AI训练数据市场规模将超千亿美元。其中,90%以上的数据会由生成数据提供。
第二步:寻找真实数据与合成数据的最佳配比,进一步提升模型性能。
并非所有任务都适合用大量合成数据,需要根据具体问题的特点,权衡成本和效果,找到最合理的数据组合方式。一般需要通过大量实验,以及领域知识的引导,来确定最佳的真实vs合成数据比例。 这个比例会受到合成数据质量、任务复杂度、真实数据规模等多种因素影响。找到"黄金配比"后,往往能在训练效率和结果准确性之间达成很好的平衡。
JoinAI 开发了 Chain 数据管理平台,可以为模型找到最佳的数据组合方式,真正让合成数据发挥它应有的效果。
第三步:脱离对真实数据的依赖,完全用合成数据训练高质量模型。
这是合成数据的终极目标。通过构建高保真的虚拟环境,生成大规模、多样化、细粒度可控的模拟数据。再利用世界模型、强化学习等先进算法,让模型在虚拟环境中自主学习,不断进化。 经过足够的迭代优化后,模型可以在完全合成的数据集上达到甚至超越使用真实数据训练的效果。这种范式如果得以实现,将大大降低AI开发的门槛和成本,释放数据红利。
JoinAI 为了这个终极目标,以自动驾驶数据为先落地场景, 开始探索使用模型生成的方法来获取更多更多样化的数据,推出了Terra-1世界模型。
Terra-1是一种基础世界模型,专门为自动驾驶领域生成高质量的合成数据。它由两个核心模块组成:Diffusion-Transformer模块负责生成高质量图像数据,世界模型模块用于模拟环境动态和物理规则。Terra-1能够生成视觉和物理上高度真实的驾驶环境和场景。
随着GenAI的发展,我们选择了融合两条路径的做法,采用transformer+Diffusion+world model的架构训练Terra来为自动驾驶模型提供合成数据,后续我们也测试了为机器人,工业视觉等领域生成数据,效果都有大幅提升。
参考资源:





