We will respond to you within three business days.
Better Data, Better AI, For Everyone, Forever
Submission Successful!
Thank you for reaching out to us. We have received your inquiry and are committed to responding within three working days. If you have any more questions in the meantime, feel free to contact our support team.
Hi there 😃
we are listening...
We will respond to you within three business days.
Submission Successful!
Thank you for reaching out to us. We have received your inquiry and are committed to responding within three working days. If you have any more questions in the meantime, feel free to contact our support team.
This website uses necessary cookies to ensure it functions properly, and tracking cookies to understand how you interact with it. The latter are only set with your consent.For more information, please visit our Privacy & Cookie for more information.
We use cookies!🍪
We use cookies to ensure basic functionality of the website and to improve your online experience. You can opt-in/out at any time for each category. For more details on cookies and other sensitive data, please read the full Privacy & Cookies
Strictly Necessary Cookies
These cookies are necessary for the operation of the website and cannot be switched off
Performance Cookies and Analytics
These cookies allow us to count visits and traffic sources so we can measure and improve the performance of our site
Targeting Cookies
These cookies are used to remember your choices and settings, maintain your preferences over time and recognize you when you return to our website
We use cookies!🍪
We use cookies to ensure basic functionality of the website and to improve your online experience. You can opt-in/out at any time for each category. For more details on cookies and other sensitive data, please read the full Privacy & Cookies
Strictly Necessary Cookies
These cookies are necessary for the operation of the website and cannot be switched off
Performance Cookies and Analytics
These cookies allow us to count visits and traffic sources so we can measure and improve the performance of our site
Targeting Cookies
These cookies are used to remember your choices and settings, maintain your preferences over time and recognize you when you return to our website
No matter how AI technology evolves, the trinity of algorithms, computing power, and data that drives it remains unchanged. Among these, data is often the most overlooked. Had it not been for the empirical proof of scaling laws, most people's understanding of the relationship between data and AI effectiveness might have remained no deeper than the old saying:
"As much intelligence as there is manual effort."
This pun, while mocking the past limitations of AI's capabilities ("just that, not meeting expectations"), also mocks the reality that intelligence is actually built upon layers of manual efforts, whether in data annotation or those "global customer service personnel hidden inside robots."
Yet, this joke bears a cruel bitterness for us AI practitioners. Before embarking on the journey with JoinAI, our founding team members personally experienced various setbacks due to the lack of proper or sufficient training data, which stalled AI effectiveness and aborted the reach to the stages that were otherwise within grasp, across domains like natural language processing and computer vision.
In recent years, the notion of "AI dominance" has arisen, questioning why truly functional AIs seem always to emerge from large corporations. A crucial factor is the prohibitive cost of training data for startups, which might as well be an insurmountable barrier, leaving intelligent AI unattainable without such data.
Algorithm engineers, striving to achieve the best outcomes within tight budgets, have been forced to apply every trick in the book, including research on models like "few-shot learning" that operate on "low data, low power" principles. The modest outcomes of these engineering applications speak volumes of their desperate creativity: embellishing a turd.
At this juncture, we owe our gratitude to OpenAI for their unwavering demonstration of the viability of scaling laws through undeniable facts, proving that perhaps the simplest route is indeed the shortcut.
When it comes to training datasets:
Mighty deeds come from bold attempts, the shortest path is often the most straightforward.
Gather as much data as possible for your AI, adhering to your training objectives—indeed, the more, the better.
Can Existing Data Achieve AGI?
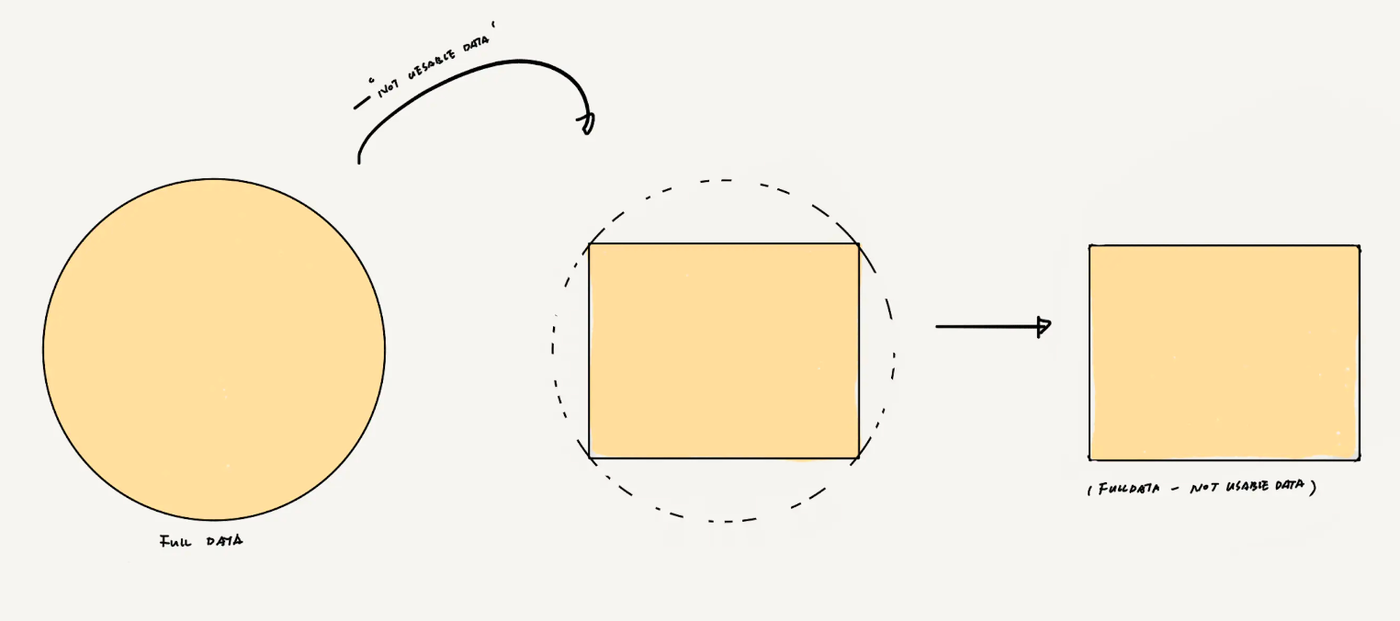
Suppose you want your AI to achieve perfect results, depicted as a circle. You would need extensive, widely covering, and richly detailed data to support this completeness, like this:👇
The total training data required to achieve the perfect effect of current AI.
This circle must be comprised of the following types of data:
Partly visible, accessible, but not usable,
Encountered but elusive,
Visible, accessible, but not free,
Visible, accessible, free but scant.
Visible, Accessible, but Not Usable Data
This type of data is like the valuables in your neighbor's house: you can see them, and physically, you might be able to obtain them, but doing so could lead to you being shot by your neighbor, facing hefty fines, or spending memorable times in jail.
Such data is very common, ranging from easily available internet data that is not clearly copyrighted but is actually traceable, to data that violates data security laws, or even someone else's private data. These are immensely valuable to your AI, but you are powerless to utilize the latter types.
Unfortunately, because you cannot obtain this part of data, your data cannot form a complete circle, and you are left with, say, a rectangle.
The data required for the perfect effect of current AI minus the privacy data.
Of course, the situation varies across different industries, and each rectangle's side lengths differ, but at best, you can only achieve a rectangle that fits perfectly within the circle. (As shown in the figure above)
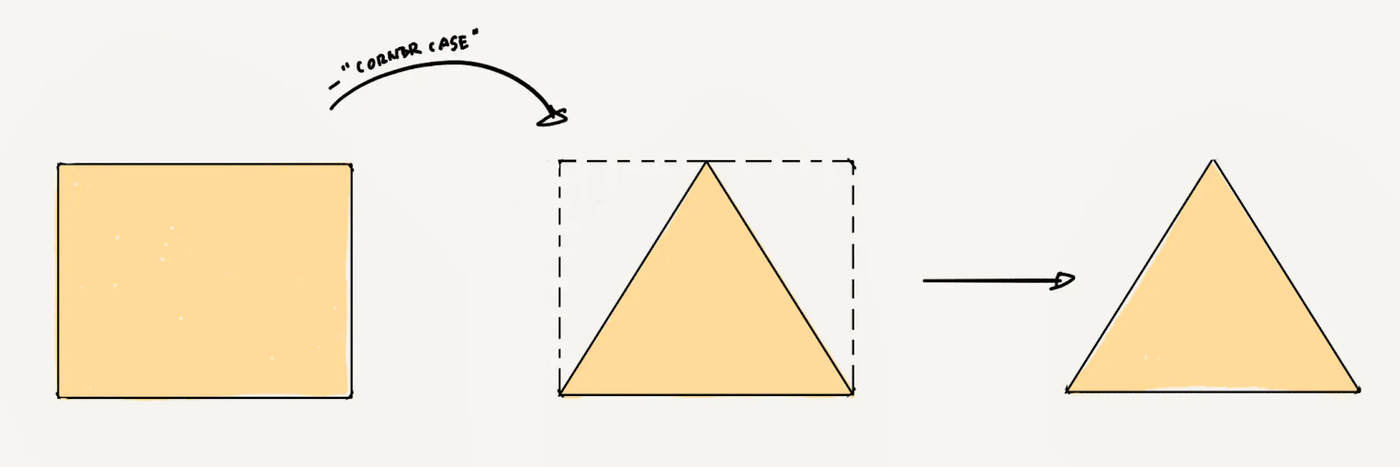
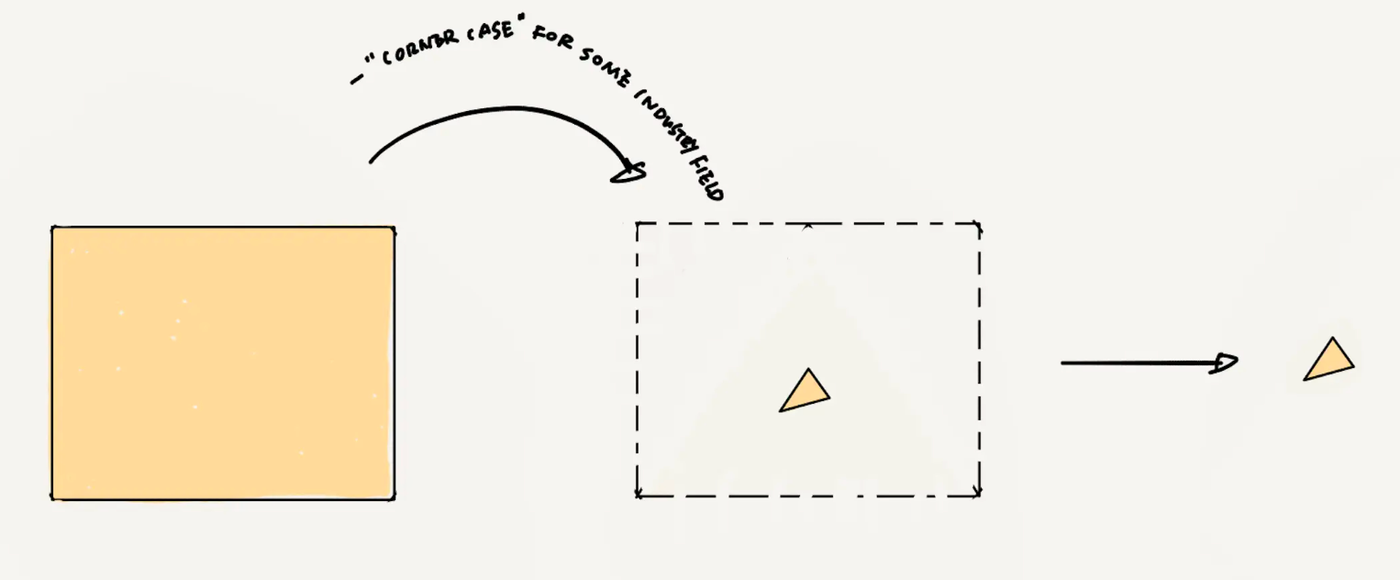
Encountered But Elusive Data
This type of data is like the Mr./Miss Right we hope to meet: most suitable and desirable, but extremely hard to obtain, known more commonly as the corner case. In scenarios where AI performance must approach 100%, corner cases are more essential than Mr./Miss Right but are scarce.
Taking the earlier example of autonomous driving: how long must you drive daily before encountering a reckless pedestrian who suddenly crosses in front of your car or runs towards it? Ideally, you'd never encounter such a scenario, but an autonomous driving system must be thoroughly prepared for it. Thus, corner cases are rare, and your rectangle must be trimmed down further, leaving you with a triangle.
The data required for the perfect effect of current AI minus privacy data and corner cases.
The shape of the largest triangle within a rectangle differs across industries and companies, depending on the corner cases each encounters. According to basics learned in data class, the largest triangle in a rectangle is a right-angled triangle.(As shown in the figure above)
Visible, Accessible, but Not Free
Now, you're left with a triangle of data, representing purchasable labeled data. Although only a triangle remains, it has stability: it can be steadily purchased with money.
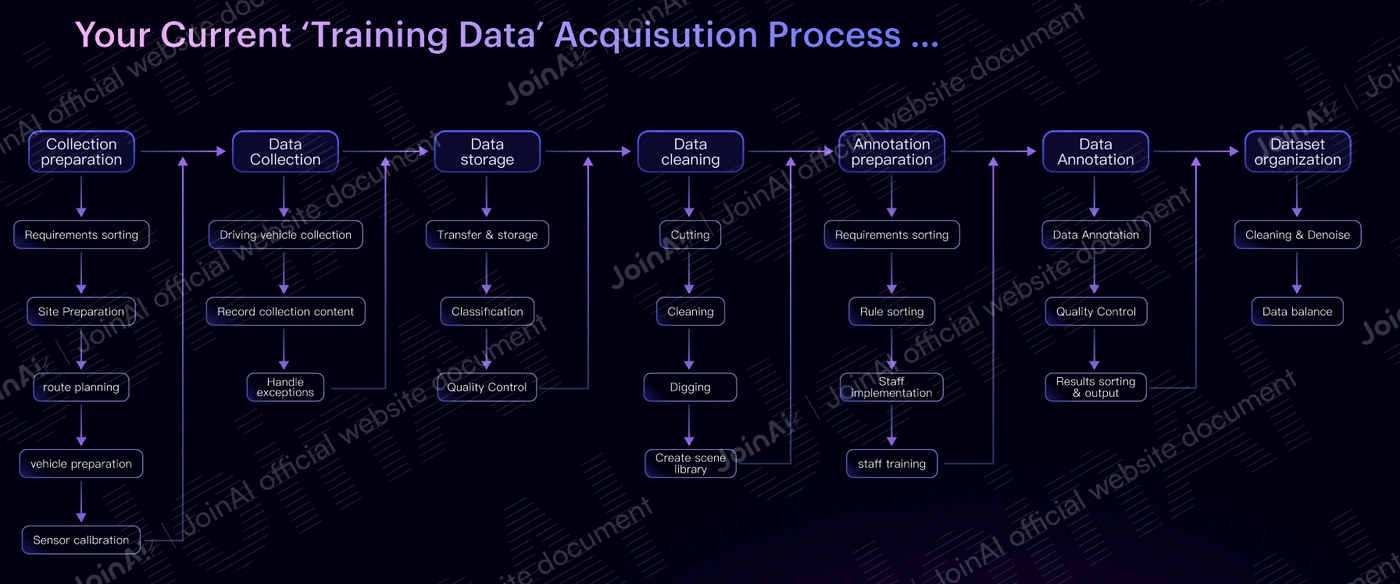
Here is its current basic acquisition process:
Your Current ‘Training Data’ Acquisition Process
A complex, lengthy, standard waterfall process is evident from the structure. Even ignoring the mythical man-months involved in each step, any issue at any stage results in a waterfall-style rework and waste. This manufacturing process, even within big companies, hasn't reached the Industrial 2.0 level, meaning the cost of this stable, purchasable data is prohibitively high for most AI projects, far from supporting the expansion of this triangle to the borders of the scaling law.
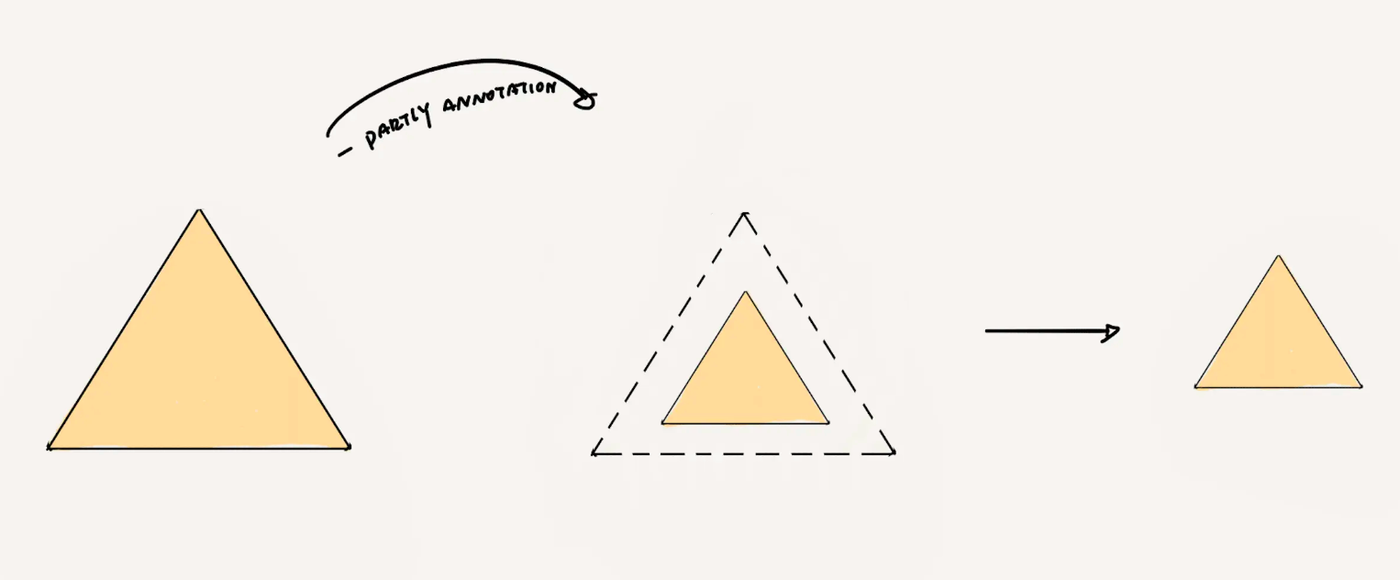
Moreover, the problems you face within this stable triangle aren't limited to money. For instance, to save costs, you might have to outsource part of the process. To ensure quality and prevent service degradation due to exclusivity, you typically need multiple suppliers. Thus, additional supply chain management is required, but even then, you can't fundamentally guarantee uniform quality from multiple suppliers. If you're the project manager, the last thing you want is for your highly paid algorithm development staff to spend 80% of their time on data handling and preparation, although you must admit this is often the reality.
So, your triangle is further discounted; it's unlikely to be the largest area right-angled triangle.
The data required for the perfect effect of current AI minus privacy data, corner cases, and some labeled data.
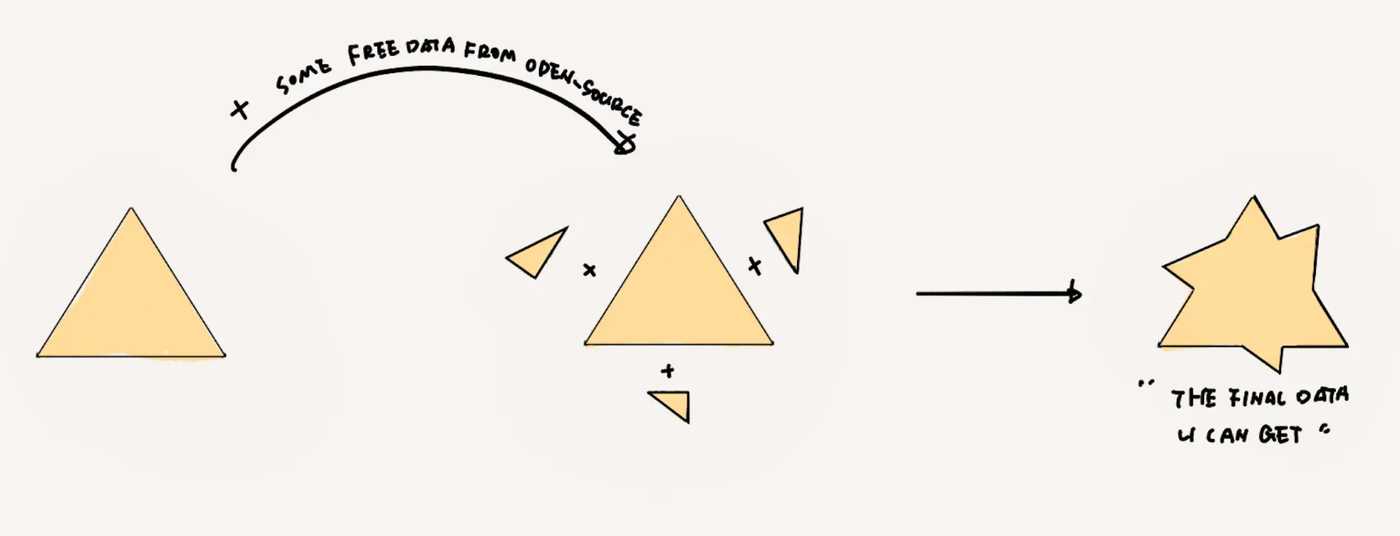
Visible, accessible, free but pitifully scarce data
The remaining part naturally leads you to think of open-source datasets. Of course, they can serve as a supplement.
We are immensely grateful to the open-source community for always contributing some freely usable good stuff. However, there's only so much available, and it's the same for everyone, making it hard to rely on for surprising expected results. They're typically used more for early lab stage exploratory validations or enriching the test set.
It must be noted that the above descriptions contain an element of ideal purity. In reality, the data shapes supporting different companies' AI performance are neither rectangles nor triangles but hybrids or shapes with less clear edges.
The data required for the perfect effect of current AI minus privacy data, corner cases, and some labeled data, plus some open-source data.
It's also worth mentioning that the proportion of corner cases and labeled data varies significantly across different industrial forms of AI. For instance, in many industrial settings, it may even be the case that no truly usable open-source datasets can be found."
Some available data in industrial scenarios (where almost all are 'corner cases')
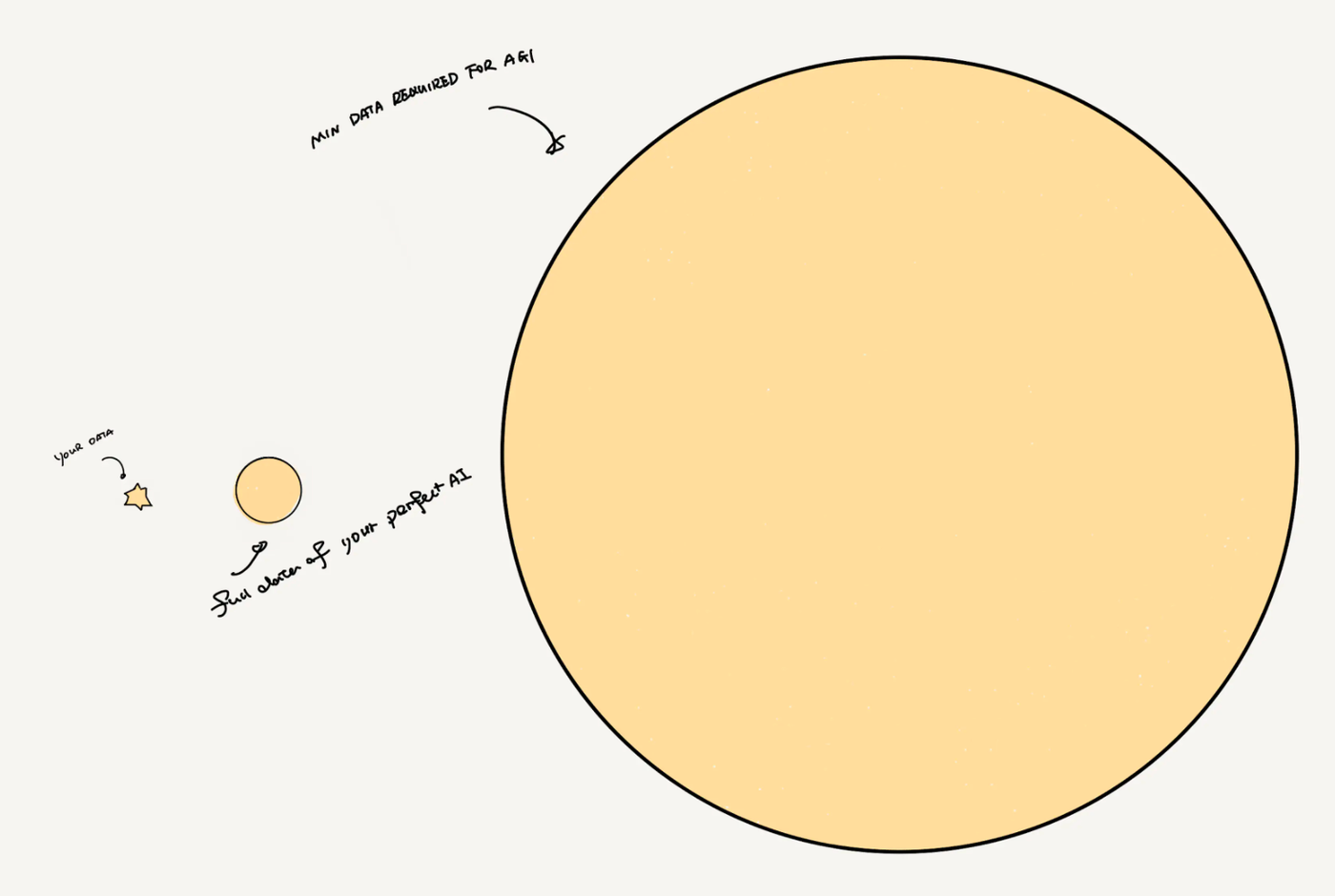
Regardless, no AI project can achieve a perfect circle of data. Even OPENAI, at best, only comes close. Naturally, if we continue to obtain data through existing methods, we might not even reach our own AI's capability boundary (that perfect circle), let alone what AGI requires.
The data you can obtain versus the data required for the perfect effect of current AI versus the minimum data required for AGI.
Unless, that is, we can adopt a method that creates vast amounts of data at extremely low costs, data that can freely achieve desired corner cases, possess privacy boundaries, and cross the threshold of privacy desires.
How mature is synthetic data technology?
Is such an idealistic, dream-like method truly viable?
Actually, it is, especially now that generative AI and world models have begun to rise. Synthetic data is increasingly playing a crucial role in AI training, becoming the optimal solution to truly liberate AI productivity and unlock the doors to the miracles of AGI. In the future that JoinAI is striving to build, training data for AI will be as accessible, affordable, and anxiety-free as electricity is for us today.
Although this might sound far-fetched, even ludicrous to some who hear about training with "synthetic data" and think it paradoxical, expanding training datasets and improving training outcomes with "synthetic data" is neither a novel concept nor a creation of the era of large models.
The technology for synthetic data has matured over time.
In the field of computer vision, the concept of synthetic data can be traced back to its early experimental stages when researchers began using basic graphic engines to generate images for testing algorithm performance. Later, with the maturation of GAN (Generative Adversarial Networks) and VAE (Variational Autoencoder) technologies, synthetic data began to be formally used to create datasets for model training. By 2014, companies in Silicon Valley were already offering services using "synthetic data," and this year, Datagan has secured a $50 million Series B investment from Scale Venture Partners.
Today, in the image-synthetic data field, the underlying mainstream technological approaches are:
Traditional data augmentation techniques led by conventional computer vision algorithms (e.g., GAN mentioned earlier),
Simulation technology or the next-generation simulation technology incorporating nerf technology,
End-to-end model-based generative AI.
Image techniques led by GAN perform well in many tasks, especially in single-object generation. Using GAN to produce training datasets can also achieve state-of-the-art results on test sets .
Originally, simulation technology was not primarily used for acquiring training data, especially in fields like autonomous driving, where simulation systems are widely used for conducting mock tests. However, the idea of utilizing data extracted from a testing system for training assistance does indeed sound uniquely appealing and superior, but the reality is not so simple. When researchers used game data from what was then considered the most physically realistic game, GTA, as a substitute for simulation data (due to GTA's higher realism compared to contemporary simulation systems) for training and testing, they found that features failed to converge, deducing a dimensional barrier between this type of generated data and real data. This issue has taken a new direction with the emergence of generative AI technology. On one hand, enhancing simulation systems with NeRF technology can reduce the effects of the dimensional barrier, but the problem remains that the training of such models is still limited by data collected from real-world settings, and it cannot create something from nothing. Moreover, although the dimensional barrier in simulation-generated data is somewhat reduced, it is still insurmountable.
On the other hand, the application of GEN AI has spawned core generative AI technologies for "synthetic data," which offer significant advantages in terms of generality, realism, controllability, and scalability, most importantly without the issue of data dimensional barriers.
Moreover, facts speak louder than words. We have also received positive feedback in practice, during commercial implementations, and through actual data verification with clients, such as the data displayed on the sixth screen of our official website's homepage, which we obtained client permission to showcase.
Controversy or Challenge?
Of course, we do not consider this technology to be flawless. Whether it's GENAI or world models, from a technical standpoint, we only see it as a beginning. There are naturally many controversies and areas for improvement.
For instance, some argue that synthetic data fundamentally differs from traditional data because it is generated by models, lacking direct human elements. This indicates that synthetic data might miss the subtle nuances naturally present in human-generated data. However, we believe that the inherent randomness of generated data adequately covers this issue. In a sense, complete randomness can even encompass predictable human regularities.
Others, while appreciating the practicality of "synthetic data" in improving data quality to enhance model performance, worry about whether synthetic data can expand the knowledge scope of models beyond what the models themselves can infer. We think this concern is related to another worry.
This worry concerns a significant risk that improper use of synthetic data might lead to: creating an echo chamber where AI systems cyclically train on outputs generated by similar systems, potentially causing innovation to stagnate. In other words, training AI models on the outputs of previous AI systems might create a feedback loop, limiting the new models' potential to surpass the old ones. Alternatively, we might call this model cannibalization, but we believe there's no need for excessive worry. The core issue causing model cannibalization lies not in synthetic data itself but more in the application methods. Regarding this, we recommend reading our other article: "Can Synthetic Data Lead to Model Cannibalization?"
We welcome any controversy.
Controversy means it's being truly used, and it also means that problems will be exposed. JoinAI's journey with synthetic data is just beginning. To realize our dreams, we will steadfastly continue on this path. It's precisely because of this that we welcome the emergence of any controversy. Every member of JoinAI maintains the most open and optimistic attitude toward controversy. For us, who hold a simple technological faith, difficulties are never more numerous than solutions.
Final Thoughts
Whenever people talk about "AI intelligence not being separable from training data," no matter how it's expressed, it doesn't change the fact that it sounds difficult to get excited about, utterly unsexy, and frustrating. Compared to this plain truth, we inevitably prefer stories of "making much out of little" or "using minimal effort to move a great weight," such as the once-popular concept of few-shot learning (the idea that good AI effects can be achieved with a small amount of training data).
From a human nature perspective, it's hard for us to restrain ourselves from seeking shortcuts. Moreover, from a scientifically dialectical perspective, even if ChatGPT has proven that the scaling law is the shortcut, it doesn't mean that the path to "intelligence emergence" is limited to the scaling law alone.
However, as long as humanity doesn't cease exploring AI/AGI, we must still face the fact that "the existing data in the real world" cannot meet the basic conditions for training, and the exploration of "synthetic data" and its related technological paths is humanity's dream shortcut.
In JoinAI's data methodology, there's a core principle formula:
Better data = (Better data AI fit x Better data acquisition methods x Better data selection methods) / Better data management methods.
Only the best synthetic technology can simultaneously maximize all three factors within the parentheses. And this is what JoinAI has been striving for.