We will respond to you within three business days.
Better Data, Better AI, For Everyone, Forever
Submission Successful!
Thank you for reaching out to us. We have received your inquiry and are committed to responding within three working days. If you have any more questions in the meantime, feel free to contact our support team.
Hi there 😃
we are listening...
We will respond to you within three business days.
Submission Successful!
Thank you for reaching out to us. We have received your inquiry and are committed to responding within three working days. If you have any more questions in the meantime, feel free to contact our support team.
This website uses necessary cookies to ensure it functions properly, and tracking cookies to understand how you interact with it. The latter are only set with your consent.For more information, please visit our Privacy & Cookie for more information.
We use cookies!🍪
We use cookies to ensure basic functionality of the website and to improve your online experience. You can opt-in/out at any time for each category. For more details on cookies and other sensitive data, please read the full Privacy & Cookies
Strictly Necessary Cookies
These cookies are necessary for the operation of the website and cannot be switched off
Performance Cookies and Analytics
These cookies allow us to count visits and traffic sources so we can measure and improve the performance of our site
Targeting Cookies
These cookies are used to remember your choices and settings, maintain your preferences over time and recognize you when you return to our website
We use cookies!🍪
We use cookies to ensure basic functionality of the website and to improve your online experience. You can opt-in/out at any time for each category. For more details on cookies and other sensitive data, please read the full Privacy & Cookies
Strictly Necessary Cookies
These cookies are necessary for the operation of the website and cannot be switched off
Performance Cookies and Analytics
These cookies allow us to count visits and traffic sources so we can measure and improve the performance of our site
Targeting Cookies
These cookies are used to remember your choices and settings, maintain your preferences over time and recognize you when you return to our website
Can synthetic data cause the model to self-cannibalize? | JoinAI
Can synthetic data cause the model to self-cannibalize?
Jun 6, 2024 /
pxiaoer
Preface:
Model cannibalism refers to the phenomenon where a new generation of models is trained entirely on data generated by the previous generation, leading to a decline in performance due to self-digestion. This article will introduce the concept of synthetic data in detail and explain under what circumstances model cannibalism occurs and how we can avoid it.
What is synthetic data?
Synthetic data is artificially created information intended for training or testing machine learning models. It can mimic real-world operations or production data and help us train machine learning models.
Currently, the major benefits of synthetic data include:
Minimizing restrictions related to regulated or sensitive data
Customizing data to match conditions not allowed by real data
Generating large-scale training datasets without manual labeling
Significantly reducing data costs for models
Helping researchers improve model performance
Why is synthetic data so important in the era of large models?
Under the influence of Scaling Laws, researchers need large-scale accurately labeled datasets when training AI models. We have also found that neural networks can achieve higher accuracy when trained on more diverse data. However, collecting and labeling these large datasets containing billions of objects is time-consuming and expensive, beyond the means of average-sized companies.
The synthetic data we are introducing today can significantly reduce the cost of training data. For example, if training images from data labeling services cost $1, the cost could be as low as $0.01 using artificially synthesized data, making it feasible for many small companies to undertake training large models.
Besides cost reduction, synthetic data also helps solve privacy issues related to sensitive data. Compared to real data, it can reduce bias, as real data may not accurately reflect all information in the real world. Synthetic data can provide greater diversity through rare cases that are difficult to obtain from real data, providing effective data for more scenarios for the model.
What is a synthetic dataset?
A synthetic dataset is a dataset containing algorithmically generated data rather than real records. The main purpose of synthetic datasets is to provide generic data that meets machine learning training purposes.
Synthetic data has specific attributes to be useful for machine learning models. Synthetic datasets may contain numerical, categorical data or unstructured data such as images and videos. When constructing datasets, it is crucial to control the random process of generating data based on statistical distributions or generative models to ensure sufficient data diversity.
What are the use cases for synthetic data?
LLM Field
Synthetic data can accurately enhance original data. High-quality synthetic data can replace actual sensitive production data. In the LLM field, using algorithms to generate data for model training has always been a hot research topic.
In OpenAI's paper "Improving Image Generation with Better Captions", OpenAI uses algorithms to generate more detailed descriptions of images to better train text-to-image models.
Image caption generation in DALL-E 3 paper
Hugging Face has also open-sourced a text generation project called Cosmopedia, where they attempt to use algorithms to generate a large-scale text dataset for LLM pre-training. NVIDIA's Nemotron-4 model directly used 98% synthetic data in its alignment process.
Cosmopedia dataset on Huggingface
Most common applications of synthetic data in the LLM field:
Testing: Synthetic test data is easier to generate than rule-based test data and provides flexibility, scalability, and authenticity. There are also startups using synthetic data for opinion surveys.
Model Training: AI model training now increasingly relies on synthetic data. Current internet data is no longer sufficient, and to continue training larger models, more diverse data is needed, making synthetic data a necessity. Data synthesis can enhance real data and oversample rare events or patterns, allowing algorithms to train more effectively. Synthetic training data often performs better than real data and is crucial for building high-quality AI models.
Model Optimization: Synthetic data is used in both model alignment and self-iteration. OpenAI's CriticGPT uses GPT-4 to generate data to train CriticGPT, which is used to find errors in GPT-4.
Content Governance: Synthetic data helps eliminate biases present in real-world data. It is also useful for stress-testing AI models with data points that rarely occur in the real world. Synthetic data is crucial for explainable AI and provides insights into how models behave.
Embodied Intelligence Field
In DeepMind's paper "Genie: Generative Interactive Environments", models can be used to generate robot operation videos for training robot models.
In the paper "RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots", GenAI tools are used to simulate realism and diversity, while Wayve's "GAIA-1: A Generative World Model for Autonomous Driving" can generate long-tail data needed for end-to-end autonomous driving models, easily obtaining data that is difficult to collect in real environments.
GAIA-1 generated video example
Most common applications of synthetic data in the embodied intelligence field:
Synthetic data is widely used in the embodied intelligence field. It can complement real-world data deficiencies and accelerate model training and testing. Here are some specific use cases:
Robot Simulation Training: Generate a large amount of realistic scene and object data in virtual environments for training robot perception, planning, and control algorithms. This saves time and cost and avoids damaging real robots.
Autonomous Driving Simulation Testing: Use tools such as engines or models to synthesize various road scenarios, weather conditions, and pedestrian and vehicle data to comprehensively test the perception and decision-making capabilities of autonomous vehicles. Companies like Waymo and Tesla extensively use synthetic data.
Automatic Data Augmentation: Synthesize more samples based on existing real data to expand the training set. For example, create new images by changing backgrounds and lighting to improve the robustness of visual models.
Long-tail Data Generation: Many tasks need to deal with various rare and complex scenarios, but such real data is difficult to collect. In this case, customized synthesis can be done according to needs, such as pedestrians in different poses or street scenes in extreme weather.
Privacy Protection: Robot deployment may involve collecting private data. Using synthetic data instead of real data for public sharing can avoid legal risks.
Controlling Data Distribution: Control data balance by generating arbitrary scene and object combinations. It's difficult to collect certain scenarios on a large scale in reality, but synthetic data can achieve this.
In summary, the advantages of synthetic data in terms of data volume, cost, and privacy have become prominent. Combining synthetic data with real data will play a greater role in future autonomous driving, robot development, and testing.
What are the challenges of synthetic data?
Self-cannibalization phenomenon of synthetic data
The paper "Self-Consuming Generative Models Go MAD" discusses the potential self-cannibalization (self-consumption) phenomenon of synthetic data.
The paper proposes three self-cannibalization cycles:
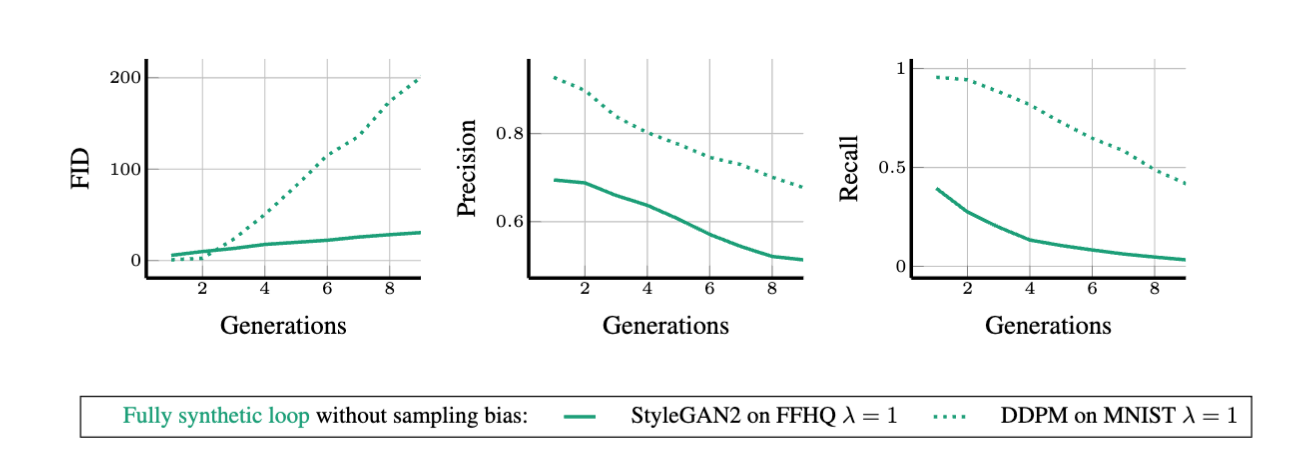
Fully Synthetic Cycle: Each generation of models is trained only using data synthesized from the previous generation model.
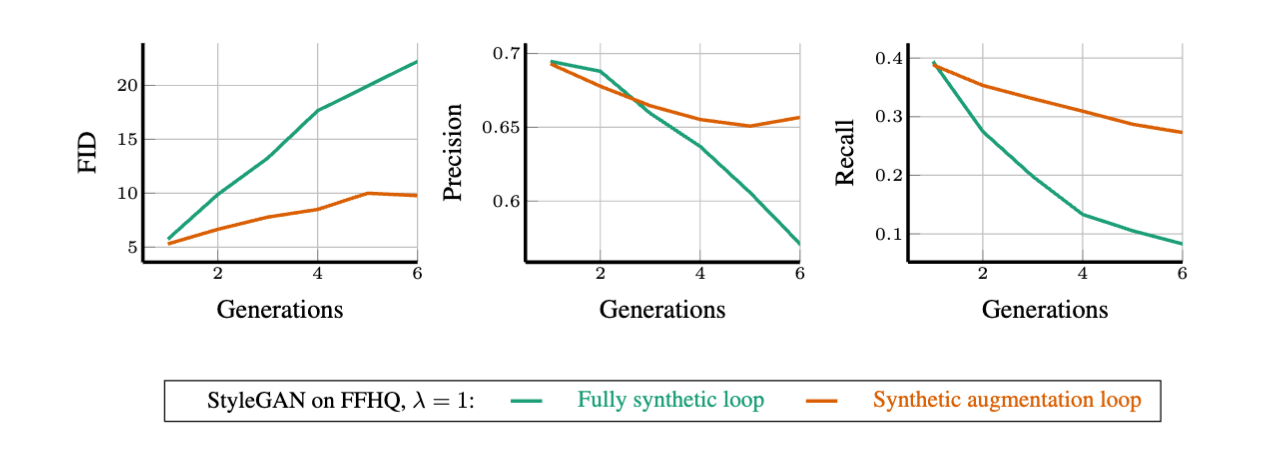
Synthetic Augmented Cycle: Each generation of models is trained using a combination of synthetic data from the previous generation model and a fixed real training dataset.
Fresh Data Cycle: Each generation of models is trained using a combination of synthetic data from the previous generation model and new real data for each generation.
The results show that without sufficient fresh real data, future generative models are destined to suffer from model self-cannibalization disorder, where their quality (precision) or diversity (recall) will gradually decrease, and generation will be amplified.
Figure 1
Figure 2
Figure 1 above shows that in a fully synthetic cycle, training generative models specifically on synthetic data without sampling bias will reduce the quality and diversity of synthetic data. Figure 2 shows the synthetic augmented cycle, where fixed real training data may delay but cannot prevent madness.
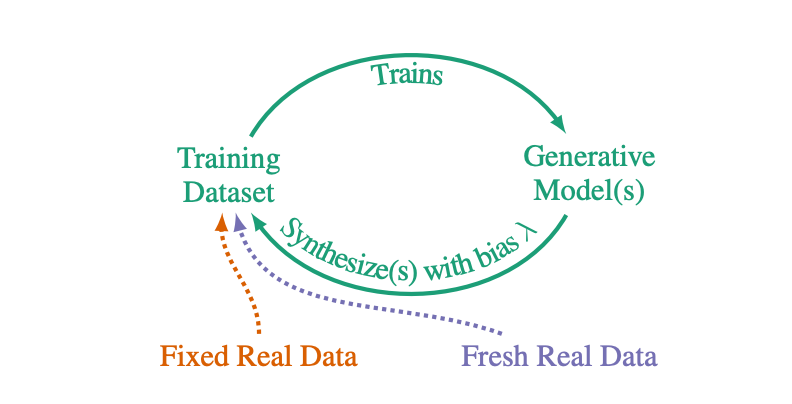
The paper also proposes a solution, which is the fresh data cycle. Experiments show that a limited amount of synthetic data can improve distribution estimation in the new data cycle because synthetic data effectively transfers previously used real data to descendants and increases the effective dataset size.
Generate a data cycle diagram for adding data to the training set
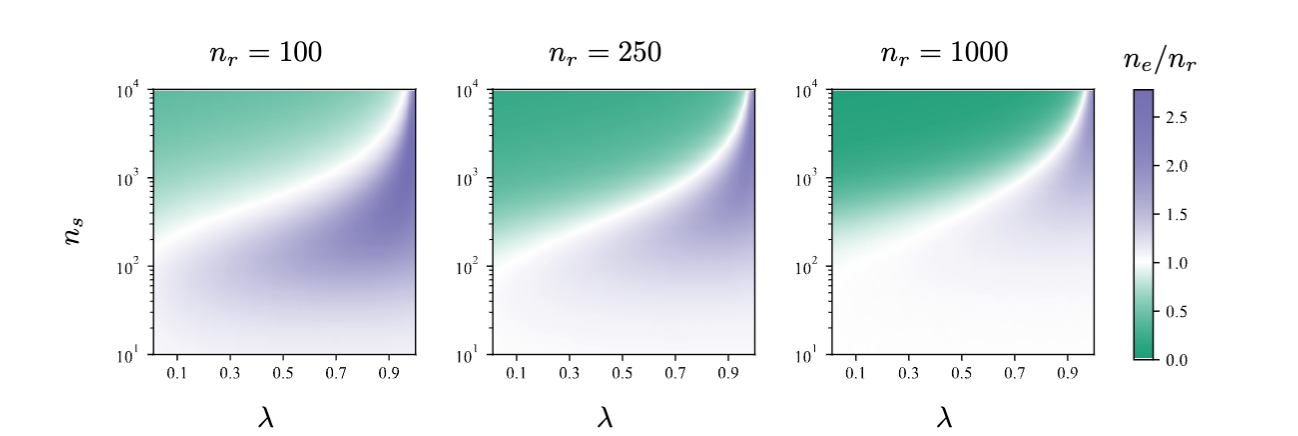
Moreover, the authors found that in the new data cycle, sampling bias reduces the acceptable size of synthetic samples. This indicates that we need to understand how much scarce real data is needed to avoid falling into model self-cannibalization.
Generate a rendering of how much data is added to the data
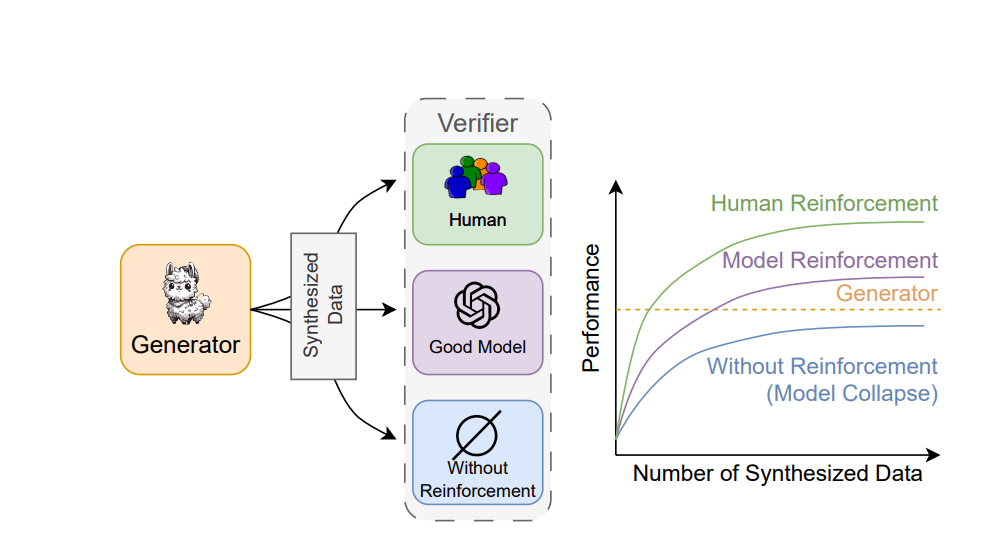
In the paper "Beyond Model Collapse: Scaling Up with Synthesized Data Requires Reinforcement", the authors found that when using synthetic data in large model fine-tuning, without using reinforcement learning, it will fall into model collapse, specifically manifested as:
The figure in the paper illustrates the effect of synthetic data with and without reinforcement learning
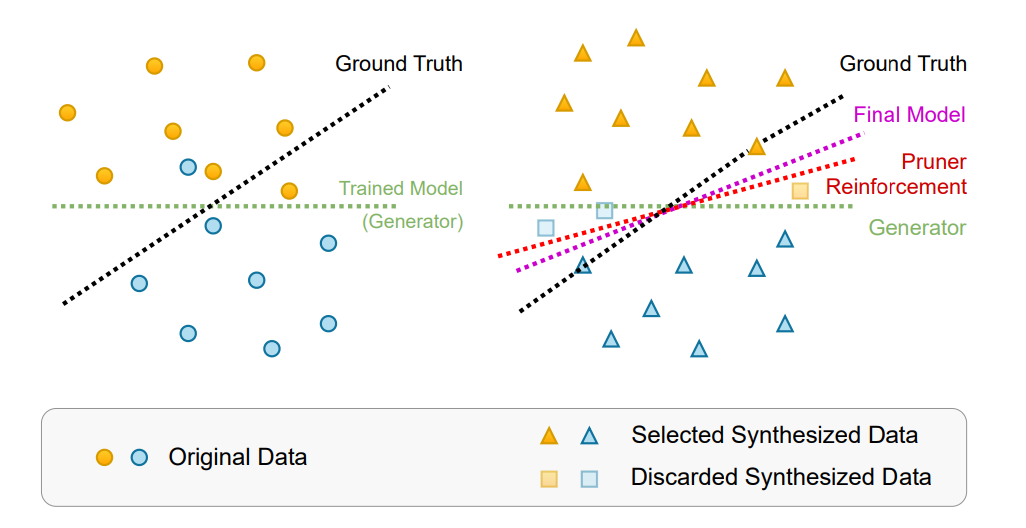
Fine-tuned large models using only synthetic data will lead to a decline in model performance, but if a selector is added, this will not occur.
Comparison of original data and selected synthetic data
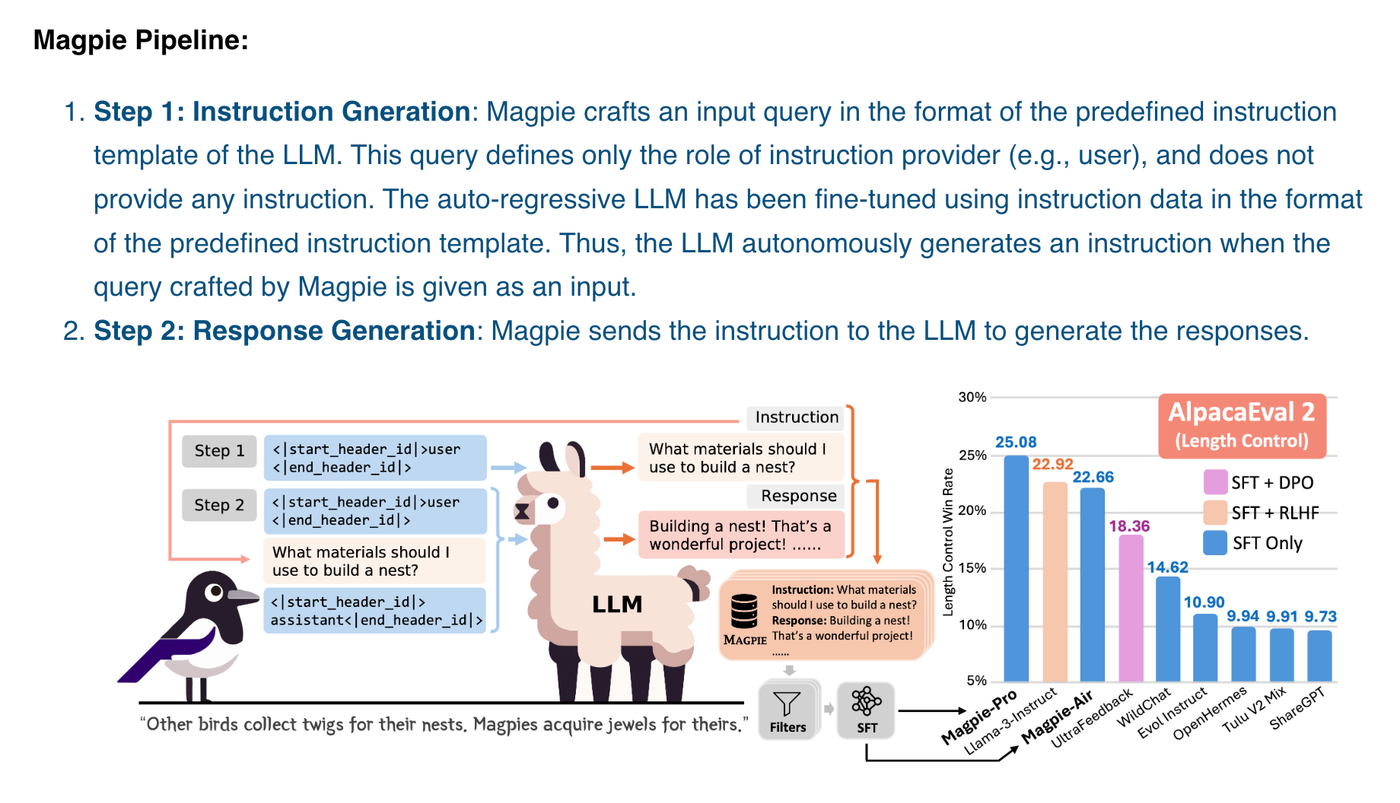
In the paper "Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing", researchers proposed a large-scale alignment data self-synthesis method for LLMs, and the effect reached SOTA.
The paper is accompanied by pictures describing the steps of synthetic data SFT.
Based on these three papers, maintaining the diversity of training data and not using all synthetic data will prevent these concerns, including self-cannibalization, from occurring.
Challenges in implementing synthetic data
Generating synthetic data is an effective means to solve problems of data scarcity, long-tail data, and privacy protection. However, this process is not without challenges.
Firstly, scalability is a key issue in synthetic data generation. To maintain optimal performance and avoid content self-cannibalization, generation systems must curate diverse prompts covering a wide range of topics while minimizing repetitive outputs. This becomes particularly difficult when scaling up, requiring carefully designed algorithms and strategies.
Secondly, the problem of dataset contamination cannot be ignored. Synthetic data may inadvertently include samples from test benchmarks during the generation process, which will seriously affect model evaluation and performance. Therefore, it is crucial to detect and ensure that the generated data does not contain benchmark contamination. This requires the development of advanced data detection techniques to identify and exclude potential sources of contamination.
Computational power requirements are another important factor in the synthetic data generation process. Synthetic data essentially replaces data with computational power, which undoubtedly increases additional computational demands. As the data scale expands, the demand for computational power will also increase accordingly, requiring more efficient algorithms and more powerful hardware support.
Data quality and consistency are the foundation of the effectiveness of synthetic data. The generated data must maintain consistency with real data in format, structure, and semantics, otherwise it may affect the performance of downstream tasks. To this end, it is necessary to establish strict quality control mechanisms to screen and filter the generated data to ensure it meets expected standards.
Privacy and security issues are challenges that must be faced in synthetic data generation. Although synthetic data does not directly come from real users, generative models may inadvertently memorize and reproduce sensitive information, bringing risks of privacy leakage.
Domain adaptability is another key point in synthetic data generation. Different domains and tasks have different requirements for data, and synthetic data needs to be adjusted and optimized for specific domains and tasks. This not only requires in-depth domain knowledge but also close collaboration with relevant experts to ensure that the generated data can meet specific needs.
Evaluating and validating the effectiveness of synthetic data and its impact on downstream tasks is a complex process. It is necessary to establish appropriate evaluation metrics and benchmarks to quantitatively measure the quality and performance of synthetic data. In addition, extensive experiments and user studies are needed to verify the effectiveness of synthetic data in practical applications.
Finally, social bias and fairness issues cannot be ignored. Synthetic data may amplify or introduce social biases, leading to unfair decisions. To this end, measures need to be taken to identify and eliminate biases in synthetic data to ensure that the generated data is fair and unbiased. This requires in-depth analysis of potential biases in the data generation process and the development of corresponding algorithms and techniques to reduce the impact of these biases.
In summary, the generation of synthetic data is a multi-faceted challenge involving scalability, dataset contamination, computational power requirements, data quality and consistency, privacy and security issues, domain adaptability, evaluation and validation, and social bias and fairness. To overcome these challenges, it is necessary to comprehensively apply advanced technologies and strategies to ensure the quality and effectiveness of synthetic data.
JoinAI's work on synthetic data
Step 1: Use synthetic data to enhance data diversity and improve model accuracy.
In many AI application scenarios, obtaining large-scale, high-quality real labeled data is very difficult and expensive, especially for some long-tail, extreme, and abnormal situations. Synthetic data can generate these samples through 3D modeling, physical simulation, and other technologies to complement the deficiencies of real data. By increasing the diversity of training data, models can learn more comprehensive feature patterns, improving their generalization ability and thus achieving higher accuracy in practical applications. Synthetic data at this stage mainly serves as a supplement to real data.
Step 2: Find the optimal ratio between real data and synthetic data to further improve model performance.
Not all tasks are suitable for using large amounts of synthetic data. It is necessary to weigh the costs and effects according to the characteristics of specific problems to find the most reasonable data combination method. Generally, it requires a large number of experiments and guidance from domain knowledge to determine the optimal ratio of real vs. synthetic data. This ratio will be affected by various factors such as the quality of synthetic data, task complexity, and the scale of real data. After finding the "golden ratio", it often achieves a good balance between training efficiency and result accuracy.
Step 3: Break away from dependence on real data and train high-quality models entirely using synthetic data.
This is the ultimate goal of synthetic data. By building high-fidelity virtual environments, generate large-scale, diverse, and finely controllable simulation data. Then use advanced algorithms such as world models and reinforcement learning to let models learn autonomously in virtual environments and continuously evolve. After sufficient iterative optimization, models can achieve or even surpass the effects of training using real data on completely synthetic datasets. If this paradigm can be realized, it will greatly lower the threshold and cost of AI development and release data dividends.